ВЕРОЯТНОСТНЫЙ СИНТАКСИЧЕСКИЙ АНАЛИЗАТОР А.М.Андреев, к.т.н., доц. МГТУ им. Н.Э.Баумана, Д.В.Березкин, к.т.н., директор НПЦ “ИНТЕЛТЕК ПЛЮС”, А.В.Брик, аспирант МГТУ им. Н.Э.Баумана, Ю.А.Кантонистов, ведущий разработчик НПЦ “ИНТЕЛТЕК ПЛЮС” контактный тел. (095) - 177 -35 -11 Введение Настоящая работа связана с одной из наиболее известных задач в области искусственного интеллекта — задачей машинного понимания текста на естественном языке (ЕЯ). Исследование этой проблемы началось еще на рубеже 60-х — 70-х гг.; с тех пор было предпринято множество различных попыток ее решения. Созданы десятки экспериментальных программ, способных вести диалог с пользователем на естественном языке. Однако широкого распространения такие системы пока не получили — как правило, из-за невысокого качества распознавания фраз, жестких требований к синтаксису “естественного языка”, а также больших затрат машинного времени и ресурсов, необходимых для их работы. Практически во всех системах машинного понимания текста используется ограниченный естественный язык, поскольку полной и строгой формальной модели ни для одного естественного языка пока не создано. В последнее время начали активно использоваться различного рода интеллектуальные информационные системы, в том числе и выполняющие обработку текстов на естественном языке. Один из классов таких систем образуют информационно-поисковые системы (ИПС), ориентированные на естественно-языковое общение с пользователем. Одним из ключевых элементов такой ИПС является лингвистический процессор (ЛП). Задача ЛП — преобразование естественно-языкового предложения (или даже целого текста) в некоторый набор семантических структур, являющихся формальным представлением “смысла” исходного предложения или текста. Иногда ЛП решает также и обратную задачу — синтез текста (как правило, ответа на запрос) на основе этих семантических структур. Классическая структура лингвистического процессора содержит три последовательных блока — для морфологического, синтаксического и семантического анализа текста. Кроме того, при подготовке исходных данных для работы ЛП может использоваться блок лексического анализа, осуществляющий фрагментацию исходного текста на предложения, а затем на слова, числа и знаки пунктуации. Будет ли этот блок непосредственно входить в состав ЛП, или станет частью его программной оболочки — зависит от конкретной задачи, на которую ориентируется данная ИПС. Лексический и морфологический анализ текста на ЕЯ не представляют серьезных трудностей для программной реализации. Первый сводится к стандартному лексическому анализу, применяемому для формальных языков (например, с помощью таблицы переходов), а второй — к поиску словоформы в базе данных (морфологическом словаре). Наибольшую трудность для разработки представляют механизмы синтаксического и семантического анализа. В некоторых ЛП эти функции реализованы совмещенными — в них выполняется очень глубокий синтаксический анализ с одновременным преобразованием распознаваемых синтаксических отношений в семантические. В предыдущих работах авторов [1,2] был описан формально-грамматический алгоритм синтаксического анализа, опирающийся на объектно-ориентированное представление правил грамматики. Анализатор успешно справлялся с простыми тестовыми примерами, однако практическое применение его в ИПС требует привлечение к проекту профессионального лингвиста. В настоящей работе предпринята попытка исследования статистических (вероятностных) алгоритмов синтаксического анализа. Главная особенность подобных методов анализа — отсутствие жесткой системы синтаксических правил, для создания которой, собственно, и требовалось участие лингвиста. Вместо нее используется обширный набор примеров — предложений, разобранных человеком вручную (или полуавтоматически, но с обязательным контролем человека-оператора). Этот набор примеров используется для “обучения” статистического распознавателя, опирающегося на известный метод дерева принятия решений (ДПР). Для создания набора примеров не требуется высокой квалификации в области лингвистики. Проблема только в количестве этих примеров — для достижения приемлемой точности анализатора их может потребоваться тысячи! Поэтому для решения таким образом поставленной задачи необходимо создать подходящий алгоритм вероятностного синтаксического анализа текстов, написанных на русском языке, и разработать специальную программу-утилиту для автоматизированного создания набора примеров. Современное состояние проблемы в области Как известно, при синтаксическом анализе текста на естественном языке основной проблемой является разрешение неоднозначностей. К этой проблеме существуют два подхода: формально-грамматический и вероятностно-статистический. Первый направлен на создание сложных систем правил, которые позволяли бы в каждом конкретном случае принимать решение в пользу той или иной синтаксической структуры; второй — на сбор статистики встречаемости различных структур в похожем контексте, на основе которой и принимается решение о выборе варианта структуры. И хотя первый подход может обеспечить более высокую точность анализатора, второй нередко оказывается практичнее. Обзор вероятностных КС-грамматик В современных зарубежных разработках, направленных на анализ ЕЯ-текстов, большое внимание уделяется именно статистическим схемам анализа. Основу большинства статистических методов анализа составляют так называемые PCFG-грамматики (probabilistic context-free grammars), являющиеся, по сути, КС-грамматиками (контекстно-свободными), в которых каждое правило дополнено некоторой вероятностной оценкой. Хотя использование простой КС-грамматики не позволяет достигнуть требуемой степени точности анализа (этот вывод был сделан еще в начале 1970-х гг.), различные схемы анализа, построенные на расширениях КС-грамматик, успешно используются в современных естественно-языковых системах. Формально PCFG-грамматику можно представить как совокупность правил вида P(Ni ® Tai | Tbi | ... |Tzi ) = qNi , где N — нетерминал, i — номер варианта интерпретации нетерминала N (i Н 1..M(N), где M(N) — число интерпретаций нетерминала N), Ta, ... Tz — термы, qNi — вероятность данной интерпретации нетерминала N. При этом M(N) Очевидным недостатком PCFG-грамматик (и вообще КС-грамматик, применяемых к анализу ЕЯ-текстов) является их слабая “лингвистичность”, т.е. невозможность учитывать разнообразные языковые конструкции, которые часто являются контекстно-зависимыми. Кроме этого, в основе PCFG-грамматики лежит допущение, что все вероятности qNi = const, иными словами, не зависят от контекста. Однако в [3] представлены данные, опровергающие это предположение. Анализ большого объема текстов показал, что частота встречаемости различных синтаксических конструкций Ni в ЕЯ-текстах сильно зависит от той роли, которую они играют в предложении. Левосторонняя вероятностная КС-грамматика Во многих работах предлагаются различные варианты улучшения стандартной PCFG-грамматики. В частности, в [3] предложена так называемая PLCG-грамматика (probabilistic left-corner context-free grammar) и соответствующий алгоритм работы синтаксического анализатора. Суть предложенного метода состоит в том, что в качестве модели ЕЯ-предложения используется левосторонняя грамматика и соответствующий ей стековый анализатор. Такой анализатор действует одновременно в двух направлениях: “сверху вниз”, пытаясь “достроить” текущий предполагаемый нетерминал, и “снизу вверх”, подбирая интерпретацию для текущего анализируемого терма. Как известно, на каждом шаге работы такого анализатора возможно выполнение одного из трех действий: удаление из стека сформированного верхнего нетерминала, присоединение текущего терма к верхнему нетерминалу в стеке, либо добавление в стек нового нетерминала. Если при анализе формальных языков на каждом шаге анализа выбор действия всегда однозначен, то для ЕЯ-предложений это далеко не так. Поэтому в модели PLCG каждому из трех действий сопоставляются вероятности, зависящие от состояния стека. Результаты сравнительных испытаний, приведенные в [3], свидетельствуют о том, что PLCG-анализатор обеспечивает на 4-5% более высокую точность анализа по сравнению с другими известными разработками, основанными на традиционной модели PCFG. Необходимо отметить, что левосторонние грамматики и стековые анализаторы для формальных языков давно известны и широко используются в теории синтаксического анализа и компиляции (см., например, [4]). Метод генетических алгоритмов Концепция оригинального морфологического и синтаксического анализатора предложена в [5]. Идея предложенного подхода состоит в том, чтобы на этапе разработки анализатора не закладывать в него лингвистических знаний (за исключением простейших), а дать возможность приобрести (сформировать) их самостоятельно во время работы. При этом анализатор самостоятельно изменяет свой набор правил в зависимости от результата разбора очередного фрагмента. Приближенно эту идею можно представить так. Пусть, к примеру, перед выполнением очередного шага анализа имеются правила: A ® BCD (1), Пусть при анализе некоторого фрагмента правила 1 и 2 оказались применимыми, а правило 3 — нет. В этом случает анализатор может сгенерировать новое правило, в правой части которого будут комбинироваться термы из правой части всех подошедших правил, а левая останется неизменной. Например, может быть создано правило A ® ECD (4). Новое правило называется “потомком”, а старые (термы из которых участвовали в формировании нового правила) — его предками. Комбинирование термов происходит случайным образом, и даже, возможно, с добавлением некоторых случайных термов, не входивших в правила-предки. Такой механизм порождения правил авторы назвали “генетическим”. После добавления нового правила весь набор правил снова применяется к фрагменту текста, затем по некоторому критерию отбираются правила с “наилучшей” применимостью, от них порождаются правила-потомки и итерация повторяется. Время от времени выполняется контроль качества анализа, достигаемого очередным поколением правил-”генов”. Численный критерий, используемый для оценки “применимости” правил и “качества” анализа также является существенной частью представленной модели. Исследования, описанные в [5], проводились вплоть до 50-го поколения правил. При этом отмечается достаточно стабильный рост качества анализа, однако форма представленных графиков зависимости качества от номера поколения позволяет предположить замедление темпов роста для поколений старше 50-го. Описанный метод заслуживает весьма серьезного внимания, но к практическому применению он пока не готов, о чем косвенным образом свидетельствуют приведенные в [5] показатели качества работы генетического анализатора. Метод распознавания образов Еще одна концепция вероятностного анализатора представлена в диссертации Д. Магермана “Естественно-языковой анализ как задача статистического распознавания образов” [ 6 ] . В этой работе рассматриваются вопросы, связанные с “обучением” и использованием статистического распознавателя, использующего для построения дерева решений алгоритм максимального правдоподобия. Под обучением в данном случае понимается формирование списка ключевых проверок и весовых коэффициентов для каждого из узлов дерева. Обучение программы-анализатора проводится автоматически (или полуавтоматически) путем анализа банка синтаксических структур (treebank). Банк синтаксических структур (БСС) может быть получен в результате “ручного” синтаксического разбора достаточно большого количества текстового материала по данной предметной области. За рубежом активно используется несколько общедоступных БСС, в частности, Lancaster Treebank (информация по компьютерной тематике), Penn Treebank (финансовая и деловая информация) и др. 1) После завершения обучения возникает необходимость “сглаживания” весовых коэффициентов построенного дерева решений, в противном случае анализатор, как правило, оказывается “чрезмерно чувствительным” (overtrained) и реагирует по-разному на некоторые идентичные синтаксические конструкции. Исследованию алгоритмов сглаживания также уделено значительное внимание в работе Магермана. Предварительные выводы Обзор современных решений в области анализа ЕЯ-текстов показывает, что чисто структурные (формально-грамматические) методы анализа постепенно вытесняются методами, в той или иной форме использующими вероятностные оценки. Методы вероятностного типа принципиально не способны обеспечить 100%-ную точность анализа, однако их результаты при работе с реальными текстами оказывается вполне удовлетворительными для многих применений. Затраты же на разработку вероятностных анализаторов могут быть существенно ниже, чем на создание исчерпывающих структурно-грамматических моделей естественного языка. В рамках работ по созданию коммерческой информационно-поисковой системы (ИПС), проводимых НПЦ Интелтек Плюс, экономические соображения для выбора типа разрабатываемого анализатора представляются весьма важными. При создании анализатора структурного типа наиболее трудоемкую часть работы —создание системы правил — выполняет лингвист, причем лингвист высокой квалификации. В то же время в конструкцию вероятностного анализатора можно закладывать гораздо меньше лингвистической информации, поскольку основную часть информации анализатор черпает из БСС при обучении. Остается проблема отсутствия общедоступных русскоязычных БСС. Располагая достаточно большим количеством официальных юридических текстов, можно с успехом предложения из них использовать для создания небольшого БСС. Задача ручного или полуавтоматического разбора (аннотирования) этих предложений требует существенно меньшей квалификации и может быть решена без привлечения специалистов в области русского языка. Наконец, еще одно замечание. Хотя проблемы, с которыми сталкиваются разработчики англоязычных систем анализа, не всегда в точности совпадают с проблемами анализа текстов на русском языке, основные методы и алгоритмы анализа являются общими и могут быть взаимно адаптированы. Исходя из приведенных выше соображений, авторы, в дальнейшем, основное внимание в настоящей работе уделили развитию объектно-ориентированного синтаксического анализатора [1,2] с использованием алгоритмов вероятностных грамматик. Статистический анализатор для русского языка В работе [6] выдвигается гипотеза о возможности полного отказа от использования структурно-грамматического блока анализатора. Как известно, разработка и отладка адекватной ЕЯ-грамматики требует чрезвычайно больших затрат времени. Вместо этого автор предлагает создавать крупные БСС (затраты времени на это существенно ниже, чем на отработку грамматики) и использовать их для обучения вероятностного анализатора, использующего метод дерева решений. Задачи, решаемые таким анализатором на различных этапах разбора текста, можно интерпретировать как классическую задачу распознавания образов, с той лишь разницей, что под образом понимается набор морфологических параметров терма или синтаксическая структура предложения, а эталонные образы (вместе с параметрами, необходимыми для их идентификации) хранятся в БСС. Разработка синтаксического ЕЯ-анализатора описанного типа состоит из трех основных задач:
Очевидно, для программиста наиболее важной является вторая задача. Работа вероятностного анализатора, предложенного Магерманом, опирается на метод дерева решений, который используется как на этапе морфологического (tagging), так и синтаксического (parsing) анализа. 1) Рассмотрим этот алгоритм подробно. Метод дерева решений Напомним некоторые определения из теории информации, относящиеся к количественным оценкам распределения случайных величин. Такие оценки необходимы при описании алгоритма построения дерева решений, а также при анализе эффективности его работы. Энтропия Пусть некоторая дискретная случайная величина X с областью определения c имеет функцию распределения p(x). Энтропией переменной X называется величина H(X) = -е p(x) log2 p(x). Взаимная энтропия Пусть две случайные величины X и Y (с областями определения c и y соответственно) имеют совместную функцию распределения pX,Y(x,y). Взаимной энтропией переменных X, Y называется величина H(X,Y) = - е е pX,Y(x,y) log2 pX,Y(x,y). Условная энтропия Пусть переменная Y имеет функцию распределения pY(y), переменная X — функцию распределения pX(x), и задана функция условного распределения pY|X(y|x). Условной энтропией переменной Y при условии X называется величина H(Y|X) = - е е pX,Y(x,y) log2 pY|X(y|x) . Поскольку pY(y) = е pY,X(y,x) , то для независимых X и Y (т.е. pY|X(y|x) є pY(y)) очевидно H(Y|X) = H(Y). Относительная энтропия Пусть имеются две функции распределения: p(x) и q(x). Относительной энтропией функции p по отношению к q называется величина p(x) В статистических обучающихся алгоритмах распознавания эта величина обычно используется для оценки того, насколько моделирующая функция распределения q(x) далека от эмпирического распределения p(x), полученного экспериментально. Действительно, если "x q(x) = p(x), то D(p||q)=0, что означает полную адекватность модели q(x). Взаимная информация Введем понятие взаимной информации двух случайных величин X и Y следующим образом: pX,Y(x,y) Величина I(X,Y) характеризует степень взаимной зависимости двух случайных переменных. Для независимых X и Y (т.е. pX,Y(x,y) = pX(x) pY(y)) естественно, что I(X,Y)=0. Перекрестная энтропия Понятие перекрестной энтропии двух функций распределения p(x) и q(x) определяется следующим образом: H(p,q) = -е p(x) log2 q(x). Тогда нетрудно показать, что H(p,q) = D(p||q) + Hp(X). Дерево принятия решений В общем случае дерево принятия решений — дерево, т.е. неориентированный связный граф без циклов, узлами которого являются проверяемые гипотезы, а листьями — возможные решения. По мере продвижения от корня дерева к листьям происходит последовательное “уточнение” принимаемого решения. Существует три ключевых понятия, касающихся дерева принятия решений:
Наиболее типичным классом задач, решаемых методом дерева решений, являются задачи распознавания и классификации. Для таких задач дерево решений может рассматриваться как некоторая иерархия категорий, к которым могут относиться классифицируемые объекты. Задача метода — определить наиболее узкую категорию (лист), к которой с заданной вероятностью относится анализируемый объект. В работе [6], алгоритм дерева решений может применяться на всех этапах анализа текста, используя в каждом случае различные типы предыстории, наборы вопросов и множества исходов. В данной работе алгоритм дерева решений рассматривается применительно к морфологическому и синтаксическому анализу. Для упрощения процедуры построения дерева решений и работы с ним будем использовать только бинарные деревья. Это значит, что каждый из вопросов, связанных с узлами дерева, допускает только два возможных ответа — например, ДА и НЕТ. (любое n-арное дерево решений может быть преобразовано к эквивалентному бинарному дереву). В простейшем случае это делается так. Пусть некоторый вопрос qi имеет n возможных ответов a1...an:
Заменим узел i и вопрос qi следующим поддеревом:
Полученный фрагмент содержит те же самые ответы a1...an, что и исходный, однако использует только булевые вопросы. Некоторые эффективные способы преобразования дерева решений к бинарной форме также рассмотрены в [6]. Использование метода Общая схема использования метода дерева решений выглядит следующим образом:
Алгоритм построения дерева решений Существует несколько разновидностей алгоритма построения дерева принятия решений. Ниже более подробно описан алгоритм максимального правдоподобия (МП). Обозначения Будем обозначать переменной X предысторию, а переменной Y — исход дерева решений. Пусть c и y — множества значений переменных X и Y соответственно. Обозначим символом C набор примеров, т.е. множество пар вида (x,y), где x Оc, yОy. В дереве решений D каждому примеру предыстории x ставится в соответствие некоторый лист, обозначаемый l(x). Обозначим через ND(x) множество всех вершин дерева D на пути от корня к листу l(x), включая l(x). Обозначим через ai(n) i-го предка вершины n; другими словами, i есть длина пути в дереве от вершины n к вершине ai. Соответственно, предок вершины n будет обозначаться a1(n). Вершину дерева n можно рассматривать как некоторое подмножество множества C, такое, что для всех его элементов x путь от корня дерева до l(x) проходит через вершину n: n Ы { (x,y) О C: n О ND(x) } Пусть имеется множество булевых вопросов qi (булевым будем называть вопрос, который допускает только два ответа, например, “ДА” и “НЕТ”). Каждому вопросу поставим в соответствие два подмножества множества C. Подмножество, для всех элементов которого на вопрос qi следует ответ “ДА”, обозначим QiC: QiC = { (x,y) О C: qi (x) = “ДА”} Для всех остальных элементов множества C на вопрос qi следует ответ “НЕТ”. Обозначим это подмножество Q`iC: Q`iC = { (x,y) О C: (x,y) П QiC } Отрицание вопроса qi обозначим q`i. Пусть pin(y|x) — эмпирическая условная вероятность исхода y при условии, что текущей вершиной является n и на вопрос qi следует ответ “ДА”: | (x’, y’ ) О Qin : y’ = y | Аналогично, вероятность исхода y при условии, что на вопрос qi следует ответ “НЕТ”, обозначим через p`in(y|x): | (x’, y’ ) О Q`in : y’ = y | Описание алгоритма Алгоритм максимального правдоподобия использует в качестве исходных данных набор примеров C и множество булевых вопросов qi. На выходе алгоритма — дерево принятия решений, минимизирующее условную энтропию представленного набора примеров. Ключевым моментом при использовании алгоритма построения дерева решений является выбор критерия завершения. Критерий завершения — это некоторое правило, определяющее, в какой момент алгоритм должен прекратить дальнейшее “расщепление” вершин дерева. Необходимость критерия завершения обусловлена прежде всего тем, что по мере расщепления вершин уменьшается количество примеров под каждой вершиной, что приводит к снижению точности эмпирических оценок вероятностей pin(y|x). В некоторый момент малое количество примеров приводит к тому, что очередное расщепление оказывается недостаточно обоснованным. Как правило, оно оказывается ненужным и может привести к чрезмерной чувствительности дерева решений. Чрезмерная чувствительность резко снижает точность распознавания на контрольном примере, не входившем в обучающий набор примеров, — а следовательно, и практическую ценность распознавателя. В качестве простейшего критерия завершения будем использовать уменьшение энтропии, достигаемое в результате расщепления очередной вершины. Если уменьшение энтропии больше нуля — расщепление этой вершины будет продолжено. В противном случае вершина считается окончательно сформированной, и алгоритм переходит к следующей вершине. Формально МП-алгоритм построения дерева решений можно описать так: Начать с набора примеров C и единственной вершины n — корня дерева. Если все исходы в вершине n одинаковы, т.е. $ynО y: "(x,y)Оn, y = yn то объявить вершину n листом и завершить работу. Иначе: H`n(Y|qi) = Pr{(x,y)ОQin}ЧH(Y|qi, n) + Pr{(x,y)ОQ`in}ЧH(Y|q`i, n) = Выбрать вопрос qk , ведущий к минимальной энтропии: k = arg min H`n(Y|qi). Определить уменьшение энтропии в результате применения вопроса qk в узле n: DH(k) = Hn(Y) - H`n(Y|qk). Если DH(k) Ј 0, то объявить вершину n листом и завершить работу. Иначе:
Дерево решений при синтаксическом анализе текста Общая схема Покажем, как описанный алгоритм может быть применен к задаче синтаксического анализа текста. Если не принимать во внимание непроективные синтаксические конструкции, встречающиеся в языке достаточно редко, то процесс построения дерева зависимостей для ЕЯ-предложения может быть представлен следующим образом. 1. Для каждого слова в предложении создаются соответствующие терминальные узлы:
2. По определенному критерию среди узлов верхнего уровня выбирается активный узел:
3. Определяется, какое положение будет занимать активный узел в цепочке дочерних узлов при формировании узла следующего уровня. Будем различать четыре возможных положения: первый в цепочке (R),
последний в цепочке (L),
внутренний (U),
одиночный (S). 4. Шаги 2 и 3 повторяются до тех пор, пока не будет получен единственный узел верхнего уровня:
Основная задача при таком построении дерева зависимостей — определить положение каждого узла (на схемах положению R соответствует наклон стрелки вправо, положению L — наклон влево, положению U — вертикальная стрелка, положению S — двойная вертикальная стрелка). Для решения этой задачи и будет использован метод дерева решений 1) . Параметры Каждый узел в дереве зависимостей обладает определенным набором морфологических параметров. Для терминальных узлов эти параметры определяются по результатам морфологического анализа, для нетерминальных — формируются по определенным правилам из параметров дочерних узлов (чаще всего нетерминальный узел получает свой набор параметров от главного дочернего узла). Очевидно, предметом вопросов qi прежде всего должны быть значения параметров текущего узла. Кроме того, для определения положения узла могут оказаться важными параметры соседних и дочерних узлов — их тоже следует включить в множество вопросов {qi}. С одной стороны, чем полнее множество вопросов {qi}, тем больше информации принимается в расчет деревом решений. В то же время множество вопросов {qi} не должно быть слишком большим, иначе затраты времени на построение дерева решений окажутся неприемлемо велики. Заметим, что описанный алгоритм построения дерева решений требует, чтобы все вопросы qi были булевыми, в то время как большинство параметров может принимать более двух значений. Каждому значению такого параметра может сопоставляться битовая строка, полученная с помощью дерева двоичной классификации всех возможных значений. Битовая строка интерпретируется как последовательность булевых вопросов, ответы на которые кодируются нулем или единицей. Мы же ради упрощения будем в качестве битовой строки использовать просто двоичную запись соответствующего значения. При этом вопрос вида “чему равно значение параметра Р1 ?”, допускающий, к примеру, 32 возможных ответа, заменяется тривиальной последовательностью булевых вопросов: “0-й бит значения параметра Р1 равен 1 ?”, “1-й бит значения параметра Р1 равен 1 ?”, . . . “4-й бит значения параметра Р1 равен 1 ?”. Теперь определим набор параметров, которыми будет обладать каждый узел (см. Табл. 1). Таблица 1
Этот набор параметров учитывает особенности морфологической структуры русского языка. В вероятностных анализаторах англоязычных текстов, как правило, параметры t, s, f объединены в один параметр tag, имеющий смысл “часть речи” и допускающий десятки возможных значений. Обозначим k-й узел дерева зависимостей через Nk (узлы нумеруются слева направо), а отдельные параметры этого узла — через Nkw , Nkt , Nks , Nkf , Nkl , Nke , Nkс. Дочерний узел с номером j будем обозначать как NCj (если они нумеруются слева направо), или NC-j (если они нумеруются справа налево). Очевидно, значения параметров Nkw , Nkt , Nks , Nkf определяются на этапе морфологического анализа, а параметров Nkl , Nke , Nkс — по мере построения синтаксической структуры предложения. Кроме вопросов о параметрах узла N, параметрах его соседних и дочерних узлов, часто оказываются полезными вспомогательные вопросы (о числе дочерних узлов, о числе терминальных узлов, о текущем состоянии анализатора и др.). Будем обозначать такие вопросы Qetc. Формальное описание задачи синтаксического анализа Вероятностный метод опирается на традиционную формулировку задачи вероятностных методов: построить такую синтаксическую структуру T, чтобы для предложения S она являлась наиболее вероятной: P(T | S) = max P. Вероятность структуры T можно определить как сумму вероятностей структур Td, изоморфных T и построенных всеми возможными путями d: P(T | S) = S P(Td | S) В нашем случае вероятность P(Td | S) есть произведение вероятностей определения всех параметров во всех узлах структуры Td. Такими параметрами являются Nl , Nc и Ne . Вероятность определения каждого параметра задается двумя факторами: выбором активного узла и предсказанием значения параметра для него. Таким образом, можно записать P(Td | S) = P P(активный = N| контекст (dj)) Ч P (Nx | контекст (dj)) Здесь контекст (dj) — последовательные состояния структуры Td по мере ее построения. Описание моделей Для решения поставленной выше задачи необходимо прежде всего задать четыре модели:
1) Предсказание активного узла Простейшая модель предсказания активного узла предполагает равновероятный выбор любого из узлов верхнего уровня: P(активный = Nk | контекст) = 1/n, где n — число узлов верхнего уровня. В [6] отмечается невысокая точность такой модели и предлагается при предсказании активного узла использовать информацию о параметрах текущего узла и двух его соседей слева и справа: P(активный = Nk | контекст) » P (активный = Nk | Nk-2 Nk-1 Nk Nk+1 Nk+2 Qetc) 2) Предсказание параметра Nl Для предсказания метки нетерминального узла Nl Магерман рекомендует использовать информацию о параметрах двух соседних узлов слева, двух соседних узлов справа, двух первых дочерних узлов и двух последних дочерних узлов: P(Nkl | контекст) » P (Nkl | Nk-2 Nk-1 Nk+1 Nk+2 NC1 NC2 NC-1 NC-2 Qetc) Однако по мнению автора эта информация является избыточной, по крайней мере для русского языка. Наиболее существенная информация для определения Nl содержится в параметрах дочерних узлов. Поэтому в настоящей работе используется более простая модель: P(Nkl | контекст) » P (Nkl | NC1 NC2 NC-1 NC-2 Qetc) 3) Предсказание параметра Nc Для предсказания наличия смежного узла в работе Магермана используется следующая модель: P(Nkc | контекст) » P (Nkc | Nkw..l Nk-2 Nk-1 Nk+1 Nk+2 NC1 NC2 NC-1 NC-2), за исключением вопросов Nk-2с , ... Nk+2с . В настоящей работе эта модель применяется без изменений. 4) Предсказание параметра Ne Модель для предсказания положения узла: P(Nke | контекст) » P (Nke | Nkw..c Nk-2 Nk-1 Nk+1 Nk+2 NC1 NC2 NC-1 NC-2) Понятно, что предсказание параметра Ne — наиболее важная задача анализатора (синтаксическая структура определяется совокупностью значений Ne во всех узлах). Поэтому стремление использовать максимум информации для принятия решения вполне объяснимо. Тем не менее в настоящей работе предпринята попытка обойтись более экономной моделью, исключив из рассмотрения параметры дочерних узлов: P(Nke | контекст) » P (Nke | Nkw..c Nk-2 Nk-1 Nk+1 Nk+2). Алгоритм вероятностного синтаксического анализа Общая схема Непосредственно из описания задачи следует, что алгоритм вероятностного синтаксического анализа должен последовательно перебирать все возможные варианты синтаксической структуры предложения, вычислять вероятностную оценку каждого варианта и сортировать варианты по убыванию вероятности. Очевидно, наиболее вероятные варианты должны рассматриваться первыми, поскольку время, отведенное на выполнение анализа, всегда ограничено. Метод дерева решений при этом используется для определения вероятностей тех или иных значений, присваиваемых параметрам узлов Nk синтаксической структуры T по мере ее построения. Нетрудно показать, что без применения специальных ограничений пространство поиска оказывается чрезвычайно большим. Наиболее простым способом его сужения является использование определенной последовательности при выборе значений параметров в узлах синтаксической структуры. Пусть в результате морфологического анализа получена цепочка не связанных между собой узлов Nk, k Н 1..n, у каждого из которых определены параметры Nw, Nt, Ns, Nf,. Поскольку морфологический анализ не всегда однозначен, некоторые из этих узлов могут иметь более одного набора значений Nw .. Nf (т.е. более одной интерпретации). Будем считать, что у таких узлов не определен параметр Nt , а число его возможных значений равно числу возможных интерпретаций данного узла. В исходном состоянии у каждого узла не определены параметры Nl , Nе , Nс , и, возможно, Nt (для терминальных узлов параметр Nl не используется). С точки зрения структуры языка представляется логичным присваивать значения параметрам узла в таком порядке: Nt , Nl , Ne , Nc ; это справедливо как в русском, так и в английском языке. При формировании нетерминального узла параметры Nw .. Nf, как правило, наследуются им от главного среди дочерних узлов (возможно, с незначительными изменениями). Поэтому прежде всего необходимо задать правило определения главного узла среди нескольких группируемых. Очевидно, выбор главного узла во многом зависит от того, какого типа узел создается — иными словами, от параметра Nl. Зная Nl , можно легко сформулировать правило выбора главного узла. Например так: если Nl = именная группа, то главный узел = существительное, Поскольку набор группируемых узлов формируется вероятностным, а не формально-грамматическим анализатором, то описанные правила должны быть более гибкими. Их можно записать в виде таблицы, у которой первый столбец соответствует значениям Nl , второй — указывает, в каком направлении (слева направо или справа налево) следует перебирать дочерние узлы, а в последующих столбцах указаны параметры слов-кандидатов на роль главного узла (в порядке убывания вероятности). В форме такой таблицы приведенные выше правила имеют вид: ИГ |¬| сущ. | личн.местоим. | числит. | ... Выбирая главный узел, анализатор просматривает соответствующую строку таблицы слева направо и объявляет главным первый узел, параметры которого совпали с указанными в таблице. Будем называть ее “таблицей главных узлов” . Итак, для нетерминальных узлов последовательность определения параметров получается несколько иная: вначале присваивается значение параметру Nl , а затем на основе этого значения определяются параметры Nw .. Nf. После этого, как и для терминальных узлов, определяются параметры Ne и Nc. Введем массив FEATURE [1.. n], элементы которого могут принимать значения T, L, E, C или Ж. Элемент FEATURE [k] показывает, какой параметр подлежит в данный момент определению в узле Nk (соответственно, Nt , Nl , Ne , Nc , либо все параметры уже определены). В исходном состоянии анализатора массив будет содержать только значения E и T. После каждого присвоения значения параметру узла массив будет обновляться. Чтобы определить область значений каждого из параметров, введем массив VALUES [{T, L, E, C}]. Каждый его элемент в свою очередь тоже является массивом, содержащим все значения, допустимые для соответствующего параметра. Остается еще проблема выбора активных узлов, т. е. узлов, параметры которых могут определяться на данном шаге анализа. Число активных узлов при определении каждого параметра должно быть ограничено. В противном случае количество возможных способов построения одной и той же синтаксической структуры оказывается очень велико, что сильно снижает эффективность работы анализатора. Теоретически можно на каждом шаге анализа иметь всего один активный узел. Однако в этом случае каждый вариант синтаксической структуры Td будет иметь единственный путь построения ( | d | = 1 ). И хотя среди всех вариантов структуры T наверняка окажется и правильный вариант, он может и не получить наивысшей вероятностной оценки и в результате будет отвергнут. Напомним, что вероятностная оценка структуры T есть сумма вероятностных оценок всех путей ее построения Td . Вероятностные оценки для разных путей построения Td , вообще говоря, отличаются между собой, поскольку на них влияют различные параметры узлов в частично построенной структуре (см. описание моделей). Увеличивая число активных узлов на каждом шаге (а следовательно, количество путей Td) , мы тем самым увеличиваем шансы правильного варианта структуры T получить наивысшую вероятностную оценку. Эффективный способ ограничить количество активных узлов — использовать так называемое “окно построения” (DWC — derivational window constraint).. Окно построения определяет число активных узлов в зависимости от того, какой из параметров (Nt , Nl , Ne или Nc) должен определяться. Для параметров Nt и Ne в [6] рекомендовано DWC = 2, а для Nl и Nc — DWC = 1. Введем массив ACTIVE [1.. n], элементы которого — натуральные числа. Элемент ACTIVE [k] показывает, сколько “недостроенных” узлов (т. е. таких, у которых еще не все параметры определены) находится слева от узла Nk. Каждый из “недостроенных” узлов может на некотором шаге анализа оказаться активным. В исходном состоянии анализатора этот массив будет иметь вид [0, 1, 2, 3, 4, ... n-1]. После каждого присвоения значения параметру узла массив будет обновляться. Поскольку вероятностные оценки частично построенных структур Td меняются по мере их построения, анализатор должен уметь возвращаться к предыдущим вариантам (если текущий вариант оказался тупиковым, т. е. с низкой вероятностной оценкой) и продолжать исследовать их. Следовательно, понадобится массив для хранения состояний анализатора. Состоянием мы будем называть частично построенную синтаксическую структуру предложения (возможно, несвязную) в совокупности со всеми значениями параметров в ее узлах Nk. (Подробнее о переборе множества состояний см. ниже, раздел “Стеки состояний”.) Введем массив STATES [1.. ?], элементы которого будут хранить последовательные состояния анализатора. В исходном состоянии этот массив содержит один элемент — это самое “исходное состояние”, т. е. несвязную цепочку терминальных узлов, полученную на выходе морфологического анализа. Обозначим исходное состояние как INITNODE. Если в ходе анализа оказалось, что текущее состояние содержит полностью сформированный вариант структуры T, то это состояние следует запомнить где-то в другом месте и исключить из массива STATES, поскольку в дальнейшей проработке оно не нуждается. Будем называть такие состояния целевыми и отведем для них специальный массив PARSES [1.. ?]. В исходном состоянии этот массив пуст. По завершении работы анализатора массив STATES будет пустым, а массив PARSES будет содержать все найденные варианты синтаксической структуры предложения T. Наконец, нам потребуется рабочая переменная, которая будет содержать текущее состояние анализатора. Назовем ее NODE . Описание алгоритма Теперь перейдем к формальному описанию алгоритма вероятностного синтаксического анализа. Его можно представить следующей блок-схемой:
Общая структура алгоритма достаточно проста. Как уже говорилось, алгоритм сводится к циклическому перебору состояний и оценке их вероятностей. При выборе очередного состояния NODE оно удаляется из массива STATES. В анализируемом состоянии последовательно присваиваются все возможные значения каждому параметру каждого узла верхнего уровня, при этом образуются новые состояния. Для каждого нового состояния с помощью метода ДПР вычисляется его вероятностная оценка, после чего оно добавляется в массив STATES (процедура ОПРЕДЕЛИТЬ ПАРАМЕТР). Признаком завершения алгоритма является пустой массив STATES. Отметим некоторые особенности работы алгоритма. Во-первых, требует пояснений блок “Выбрать состояние NODE из массива STATES.” Механизм выбора текущего состояния — один из главных в алгоритме вероятностного синтаксического анализа, поскольку именно от него в конечном итоге зависит, насколько быстро анализатор сможет прийти к правильному варианту структуры T. Этот механизм основывается на концепции “стеков состояний” и будет подробно описан ниже. Во-вторых, не вполне очевидна схема выбора очередного параметра в нижней части схемы. Как уже говорилось, все параметры Nt .. Nc определяются последовательно для всех узлов слева направо. Однако структура естественного языка позволяет сделать ряд исключений из этого правила, ускоряющих процесс перебора состояний. В частности, параметры Nl и Nc можно определять “вне очереди”, если массив ACTIVE и значение DWC позволяют сделать данный узел активным. Кроме того, если по ходу анализа некоторый узел получил значение параметра Nl = UP, это значит, что он станет внутренним узлом для некоторого узла верхнего уровня. И если параметр Nt у такого внутреннего узла еще не определен, его также можно определить “вне очереди” — заметного влияния на вероятностную оценку структуры Td этот параметр уже не окажет. Стеки состояний Поскольку анализатор перебирает все возможные значения каждого параметра в каждом узле синтаксической структуры T, и делает это при всех возможных путях построения этой структуры, то даже с использованием эвристических ограничений (окно построения, таблица главных узлов) пространство поиска остается огромным. Более того, поскольку одна и та же структура T может строиться различными путями Td, пространство поиска является не деревом, а графом общего вида. Для того чтобы результат анализа мог быть получен за приемлемое время, необходим специальный алгоритм, который позволял бы отсекать “бесперспективные” состояния заранее, не доводя их до завершения. Следовательно, нужно уметь сравнивать “перспективности” состояний друг с другом. Использовать вероятностную оценку состояния в качестве критерия “перспективности” напрямую нельзя. Дело в том, что вероятностная оценка есть произведение вероятностей всех решений, принятых на пути к данному состоянию (см. формальное описание задачи). Это произведение быстро убывает с увеличением количества множителей. Очевидно, чем более сложное (т. е. близкое к завершению) состояние мы рассматриваем, тем больше решений было принято в ходе его построения. Поэтому вероятностная оценка сложного состояния, вообще говоря, меньше вероятностной оценки более простых состояний. При анализе это приведет к тому, что анализатор вначале будет “прочесывать” пространство наиболее простых состояний, и лишь исчерпав его, переходить к более сложным. Полностью завершенные (целевые) состояния при этом будут рассмотрены последними — значит, никакой оптимизации поиска не получается, скорее наоборот... Тем не менее вероятностная оценка может и должна использоваться при сравнении состояний друг с другом. Но чтобы сделать такое сравнение более объективным, разделим все состояния на группы. В каждую группу будут входить состояния, при построении которых было принято одинаковое количество вероятностных решений, а именно присвоений значения параметрам Nt , Nl или Ne. Внутри каждой группы состояния отсортированы по убыванию вероятности; наиболее “вероятное” состояние первым выбирается из такой группы, поэтому ее можно считать стеком. Присвоим каждому стеку номер, состоящий из трех чисел: первое будет обозначать число присваиваний значений параметру Nt, второе — параметру Nl , третье — параметру Ne :
Исходное состояние INITNODE поместим в отдельный стек с номером 000. Всякий раз, когда анализатор присваивает очередное значение параметру узла, генерируется новое состояние. Это состояние помещается в стек, номер которого получается из номера текущего стека прибавлением единицы в соответствующем поле. (Количество новых состояний, генерируемых при определении некоторого параметра в узле, равно числу возможных значений этого параметра.) В результате получается такая последовательность стеков состояний:
На схеме видно, что одно и то же состояние в стеке 101 может быть построено двумя различными путями. Напомним, что вероятностная оценка такого состояния равна сумме вероятностных оценок всех путей его построения (см. формальное описание задачи). “Целевым” назван стек, в котором состояния содержат законченный вариант синтаксической структуры T (т. е. связное дерево, покрывающее все анализируемое предложение). Поскольку разные варианты структуры T могут содержать разное число узлов (и следовательно, разное число принимаемых вероятностных решений), целевых стеков может получиться несколько. Хотя вероятностные оценки состояний сравниваются друг с другом только в пределах одного стека, для целевых стеков делается исключение. После завершения анализа состояния из всех целевых стеков выстраиваются в одном массиве PARSES, отсортированном по убыванию вероятностной оценки. Необходимость такой сортировки следует прямо из постановки задачи. А поскольку в сравнении участвуют состояния из разных стеков, снова сказывается преимущество вероятностной оценки простой структуры перед более сложной. Но если в ходе анализа этот эффект был вреден (поскольку направлял последовательность анализа заведомо неоптимальным образом), то при сравнении результатов анализа он оказывается полезным. В самом деле, если использованные вероятностные модели позволили получить несколько вариантов структуры предложения с разной сложностью, то этот эффект будет задерживать “излишне структурированные” варианты. Наиболее важной частью рассматриваемого алгоритма является механизм отсечения. Для отсечения “бесперспективных состояний” внутри каждого стека Магерман предлагает использовать так называемый “порог отсечения” l Н 0..1. Смысл этой переменной в том, что все состояния с вероятностной оценкой меньше l Pmax (где Pmax — наибольшая вероятностная оценка в стеке) считаются “замороженными” и не учитываются при выборе текущего состояния. Часто значение l оказывается одинаковым для всех стеков, хотя иногда в ходе анализа может потребоваться задать его индивидуально для определенного стека. Процедура отсечения начинается с “граничных” стеков, т. е. стеков, построенных последними и не имеющих потомков 1) . Все состояния в “граничных” стеках объявляются активными. В каждом стеке определяется значение l Pmax , и все состояния с вероятностной оценкой не ниже l Pmax достраиваются на один шаг вперед; остальные состояния в стеке считаются “замороженными” на данном шаге анализа. После этого объявляются активными все состояния — предки “незамороженных” состояний. Эта процедура отсечения повторяется рекурсивно для каждого стека S, после того как будут обработаны все стеки — потомки S. После того как процедура отсечения достигнет стека 000 и все активные состояния будут достроены на шаг вперед, процедура начинает выполняться снова, уже при других “граничных” стеках. В отличие от других стековых алгоритмов поиска, данный алгоритм не уничтожает бесперспективные состояния навсегда, а только временно отключает их. Если потомки некоторого состояния оказываются бесперспективными, то в определенный момент оно будет “заморожено”. Если это было состояние с высокой вероятностной оценкой, то порог l в его стеке может быть снижен, чтобы “разморозить” другие состояния в этом стеке и продолжить их достраивание. Хотя описываемый стековый алгоритм использует временное, а не постоянное отсечение состояний, может потребоваться установить некоторый лимит числа состояний в одном стеке — в противном случае объем памяти, занимаемый массивом STATES, оказывается очень большим. Скорее всего, отбрасывание (на этот раз постоянное) нескольких наименее вероятных состояний в большом стеке не повлияет на результат анализа. Допустим даже, что такое постоянное отбрасывание привело к ошибке анализа. Очевидно, что без отбрасывания процедура анализа все равно потратит большую часть времени на построение более вероятных состояний. В условиях ограниченного времени, отведенного на анализ, это равноценно ошибке — до отбрасываемых состояний очередь все равно не успеет дойти. Способы подготовки БСС Как уже говорилось, первым и наиболее трудоемким этапом в разработке вероятностного анализатора является подготовка БСС. В зарубежных работах эта задача решается двумя основными способами. В первом случае используется обычный текстовый редактор, в который загружается разбираемый текст, а затем оператор-лингвист вручную специальными знаками размечает морфологическую и синтаксическую структуру каждого предложения:
(пример взят из работы [6]). Здесь скобки отмечают границы синтаксических групп, а метки (выделены прописными буквами) — морфологические признаки соответствующих текстовых единиц. Символ “@” показывает наличие смежного узла для разрывных составляющих. Таким образом, текст на ЕЯ превращается в текст на некотором формальном языке (типа языка правильных скобочных структур), который на этапе обучения сканируется анализатором (с помощью любой схемы анализа формальных языков, например, стековой) и используется для построения набора деревьев принятия решений. При другом подходе к построению БСС требуется специальная утилита, обеспечивающая преобразование ЕЯ-текста непосредственно в двоичное представление его морфологической и синтаксической структуры. Такая утилита может быть сделана полуавтоматической, т.е. в ней может быть задействован примитивный структурный анализатор, который будет “подсказывать” оператору варианты разбора. При таком подходе обеспечивается не только более высокая производительность труда оператора, но и более высокая скорость обучения вероятностного анализатора на полученном материале (за счет отсутствия фазы сканирования разобранных фрагментов). Очевидным недостатком первого подхода является высокая трудоемкость создания БСС, и, самое неприятное, дополнительные возможности внесения ошибок в формируемый БСС. Ошибки на этапе создания БСС наиболее опасны, поскольку они будут учтены при обучении анализатора и “повторены” им в последующей работе; не существует способа исправить их в уже обученном анализаторе, и единственным способом их исправления является повторное обучение анализатора на исправленном БСС. Недостатком второго подхода является, во-первых, необходимость разработки дополнительной утилиты, и во-вторых, плохая переносимость полученного БСС, поскольку он оказывается привязан к конкретному формату, в котором утилита сохраняет синтаксические структуры. Как уже говорилось, за рубежом существует несколько общедоступных БСС, используемых независимыми разработчиками. Очевидно, такие БСС построены по первому способу, поскольку какого-либо стандартного способа для двоичного представления морфологической и синтаксической информации не существует, а текстовое представление (пусть даже в примитивной скобочной форме) является общедоступным. Тем не менее, в данной разработке был выбран второй подход. Интеграция продукта с разработками других производителей не планируется, а преимущества второго подхода позволяют существенно сократить сроки разработки вероятностного анализатора. Результатом данного проекта стала утилита TreeBanker, позволяющая создавать (и впоследствии редактировать) БСС на основе документов в простом текстовом формате. Программа значительно ускоряет процесс подготовки БСС, автоматизируя большинство операций по выбору главного элемента синтаксической группы и определению ее параметров. Описание проекта “Минерва” В настоящее время фирмой “ИНТЕЛТЕК ПЛЮС” выполняются работы по проекту с рабочим названием “Минерва”, целью которого является создание экспертной системы, предоставляющей пользователю возможность формирования семантического описания текста документа и помещения его в базу данных [8]. Это позволит при добавлении нового документа производить проверку противоречивости данных и анализировать семантику нового документа. Язык Минерва Структура разрабатываемой системы несколько отличается от стандартной схемы лингвистического процессора (см., например, [2, 7] ). Основное отличие состоит в использовании оригинального объектно-ориентированного метаязыка для представления семантической информации (внутреннее название языка — Минерва — послужило названием всему проекту). Кратко перечислим свойства языка Минерва , наиболее важные для взаимодействия с лингвистическим процессором. Минерва — объектно-ориентированный язык представления знаний, предназначенный, прежде всего, для формального описания нормативно-правовых документов. Средства языка позволяют описывать не только смысл отдельных предложений нормативного документа, но и реквизиты документа в целом. В качестве основной конструкции языка используется “объект”, содержащий набор свойств (полей) и операций (методов), которые может выполнять данный объект над другими объектами, или аргументом которых может служить он сам. Система методов в языке Минерва может быть легко сопоставлена с традиционными моделями управления (МУ), используемыми при машинном анализе текстов на естественном языке. Напомним, что МУ связываются с предикатами и предикативными конструкциями, имеющими один или более актантов. Как правило, каждая групповая МУ содержит, по крайней мере, одну элементарную МУ с семантической ролью “АГЕНТ”; иными словами, практически у каждого предиката подразумевается наличие некоторого главного актанта, который производит данное действие (предикат) над остальными актантами. На языке Минерва модель управления может быть выражена следующим образом: каждому актанту сопоставляется отдельный объект, а сам предикат описывается в виде метода, принадлежащего “главному” объекту; остальные объекты являются аргументами этого метода. Структура системы Выделяются четыре основных блока экспертной системы: логический анализатор текста (объединяющий в себе функции лексического, морфологического и синтаксического анализа текста документа), блок семантического анализа (выполняющий преобразование синтаксической структуры фрагмента в эквивалентное описание на языке Минерва), интерфейс языка Минерва (компилятор и механизм логического вывода) и база данных (для хранения семантических описаний документов). При этом должна быть выполнена значительная работа по выявлению и систематизации типовых языковых конструкций, используемых в текстах нормативных актов. Это обеспечит высокую степень автоматизации отображения синтаксических структур в семантические конструкции вплоть до полной автоматизации. Типовые конструкции (шаблоны) существенно упростят этап синтаксического анализа и обеспечат автоматическое преобразование выражений, записанных на естественном языке, в выражения на языке представления знаний — Минерве. Ниже представлена обобщенная структурная схема экспертной системы проекта “Минерва”:
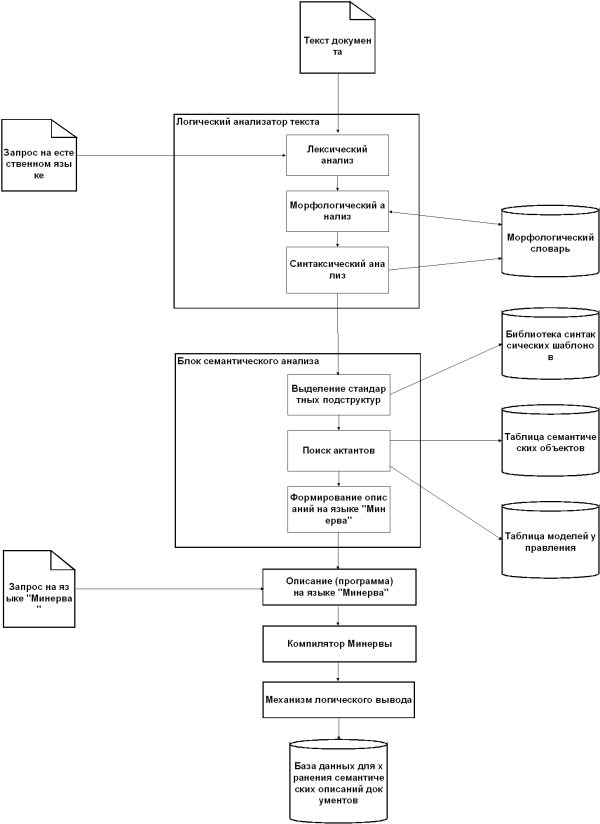
Квалифицированный пользователь, владеющий языком Минерва, может самостоятельно формировать знания непосредственно на формальном языке, основываясь на своем представлении о предметной области. И в этом случае возможные противоречия в его формулировках будут выявлены и указаны конкретные документы, с которыми конфликтуют его формулировки. В качестве исходного материала для заполнения базы знаний предполагается использовать базы нормативных актов известных информационно-правовых систем “Гарант” и “Консультант Плюс”. Логический анализатор Блок логического анализатора представляет собой, в сущности, обычный лингвистический процессор (см. [2]), из которого вынесен блок семантического анализа. Он содержит блоки лексического, морфологического и синтаксического анализа, а также морфологический словарь ограниченного русского языка. Задачей лексического анализатора является определение границ предложений, выделение слов, идентификаторов и пунктуации. Морфологический анализатор выполняет поиск слов в словаре (словарь представляет собой отдельную БД) и определяет их морфологические параметры (например, часть речи, род, число, падеж и т. д.). Синтаксический анализатор выполняет построение синтаксического графа предложения. Алгоритм его работы основывается на схеме статистического распознавателя, использующего метод дерева решений. Эта схема подробно описана в предыдущем разделе. Кроме приведенных выше доводов в пользу статистического (а не формально-грамматического) подхода к синтаксическому анализу еще одно соображение повлияло на выбор схемы анализатора. Речь идет о поведении анализатора при обработке незнакомых синтаксических конструкций. Формально-грамматические анализаторы в таких случаях либо останавливаются, выдавая сигнал о невозможности продолжать анализ, либо выдают заведомо неправильную интерпретацию фрагмента. Статистический анализатор в этих условиях просто выдает наиболее вероятный с его точки зрения вариант структуры фрагмента. А из представленной выше структуры системы “Минерва” видно, что нестандартные синтаксические конструкции все равно будут игнорироваться блоком семантического анализа. Таким образом, использование статистического метода анализа в системе “Минерва” оказывается более предпочтительным. Словарная подсистема В отличие от предыдущих работ авторов в области анализа текстов на ЕЯ [1,2], носивших исследовательский характер, данный проект нацелен на полномасштабное коммерческое применение. В связи с этим были существенно пересмотрены структура и способ реализации словарной подсистемы лингвистического процессора. Очевидно, для хранения нескольких десятков тысяч словарных записей со сложной структурой и взаимными ссылками необходимо использовать базу данных. В качестве СУБД для словарной подсистемы была выбрана Paradox 5.0, интерфейс с которой поддерживается всеми современными системами разработки приложений. Кроме того, использование СУБД для хранения морфологической информации позволяет свести задачу морфологического анализа к стандартной задаче поиска в базе данных — либо напрямую через программный интерфейс СУБД, либо средствами SQL-запросов. Общая структура словарной базы данных выглядит следующим образом:
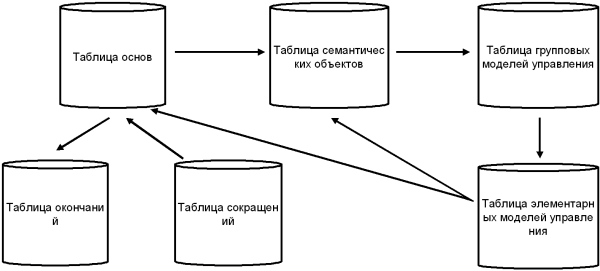
Для обеспечения большей гибкости при хранении семантической информации, связанной с каждым словом, вводится дополнительная таблица — таблица семантических объектов. Теперь семантические признаки слова (например, метапонятия или модели управления) хранятся не в таблице основ, как это было в [2], а в таблице семантических объектов. А записи основ содержат только ссылки на соответствующие семантические объекты. В результате одна запись в таблице основ естественным образом представляет сразу все омонимы данного слова — за счет нескольких ссылок на различные семантические объекты. И наоборот, несколько синонимичных основ могут содержать ссылки на один и тот же семантический объект. Еще одним дополнением к словарной подсистеме лингвистического процессора стала таблица сокращений. Поскольку даже в официальных документах существует довольно широкий набор общепринятых сокращений, их обработка оказывается необходимой. Запись в таблице сокращений имеет ссылку на запись в таблице основ, которая содержит полную форму данного слова. Остальные таблицы выполняют те же функции, что и в предыдущем проекте [2]. Полная структурная схема словарной базы данных представлена ниже.
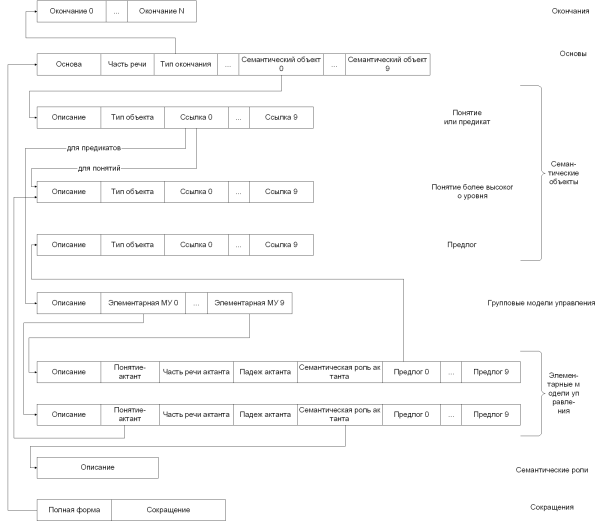
В представленную структуру не вошли внутренние файлы, необходимые для работы блока синтаксического анализа. Эти файлы создаются на этапе обучения вероятностного анализатора и хранят двоичное представление деревьев принятия решений отдельно по каждому из параметров Nl , Ne , Nc (см. описание алгоритма, приведенное выше. Исходя из соображений быстродействия для хранения этих деревьев решено использовать простые двоичные файлы, а не таблицы Paradox. Использование вероятностного анализатора Для реализации вероятностного статистического анализатора, прежде всего необходим банк синтаксических структур (БСС). Чем больше его объем, тем (теоретически) выше точность работы анализатора, обученного на данном БСС. Однако, начиная с некоторого объема, дальнейшее увеличение БСС не приводит к заметному увеличению точности анализатора. Магерман экспериментировал с БСС, содержавшем примерно 10000 предложений, и пришел к выводу, что этот объем можно считать оптимальным. Очевидно, даже с помощью специальных инструментальных средств создание БСС такого объема требует очень больших затрат времени. В проекте “Минерва” для первых опытов использован БСС объемом всего в 200—300 предложений, с последующим пополнением. Для автоматизированного создания и редактирования БСС разработана специальная утилита TreeBanker, подробное описание которой будет приведено ниже. Очень большое значение при создании БСС имеет выбор исходного текстового материала. Этот материал должен принадлежать к той же предметной области, в которой будет работать обученный анализатор. В проекте “Минерва” материалом для создания БСС служат тексты различный нормативных актов, законов и т. д. Утилита TreeBanker Назначение Разработанная в настоящем проекте программа TreeBanker выполняет две основных функции: пополнение словарной базы данных системы и полуавтоматическое создание БСС из текстовых файлов. Обе эти функции предназначены для различных стадий разработки проекта “Минерва”, а не для работы у конечного пользователя. Иными словами, TreeBanker представляет собой вспомогательное инструментальное средство, утилиту. Ее применение позволяет существенно повысить производительность труда и снизить число ошибок при подготовке БСС и наполнении словаря. Программа является развитием прообраза, предложенного в [2] и использует для автоматизированного создания синтаксического графа предложения простой формально-грамматический анализатор, впервые реализованный в проекте [2]. Заполнение словаря Пользователь имеет возможность пополнять и редактировать словари (морфологический, синтаксический, семантические) двумя путями: вручную (по командам меню) и автоматически (во время работы с текстом предложения, когда встречается незнакомое слово, синтаксическая конструкция и т. д., соответствующий словарь вызывается на экран для пополнения). Поддерживаются следующие словари:
Все словарные таблицы сохраняются в формате Paradox 5.0. Это позволяет при необходимости вносить в них исправления внешними средствами для работы с БД, например, с помощью пакета Borland Database Desktop. Создание и редактирование БСС Работа с банком синтаксических структур возможна в двух режимах: создание и редактирование. Перед началом работы в режиме создания БСС пользователь выбирает текстовый файл, предложения из которого будут использоваться для создания БСС. Затем программа последовательно выбирает из текста законченные предложения (лексический анализ), выполняет морфологический разбор всех слов в предложении (в случае неоднозначного разбора пользователю предлагается указать правильный вариант вручную) и переходит в окно редактирования синтаксической структуры. В этом окне пользователь с помощью вспомогательных автоматизирующих средств строит синтаксический граф предложения. Закончив формировать граф, пользователь сохраняет его в файле БСС, после чего программа автоматически переходит к следующему предложению, и т. д. Режим редактирования вызывается по команде меню и позволяет пользователю последовательно просматривать содержимое файла БСС, перемещаясь по нему в двух направлениях, вносить исправления в синтаксические графы предложений, а также при необходимости удалять их целиком. Описание программы Программа TreeBanker написана на языке Delphi с помощью инструментального пакета Borland Delphi 1.0 Desktop. Программа содержит следующие модули и формы:
Описание алгоритма Как уже говорилось, основной задачей утилиты TreeBanker является ускорение процесса подготовки БСС. Для этого в программе используется часть кода из [2], а именно блоки лексического и морфологического анализа, а также блок синтаксического анализа в несколько измененной форме. Общая схема работы с документом в программе TreeBanker выглядит следующим образом:
Режим редактирования БСС отличается от режима создания отсутствием шагов 1—5. Пользователь сразу попадает в окно синтаксического редактора с первым загруженным деревом из файла БСС. В ходе редактирования возможен переход к следующему или предыдущему дереву, выход с сохранением изменений или без сохранения. Рассмотрим используемые в программе алгоритмы подробнее. Лексический анализ и поиск границ предложения Достаточно тривиальный алгоритм лексического анализа [2] дополнен эвристической функцией определения начала и конца предложения. Исходными данными для лексического анализатора служит текст документа в виде массива ASCII-символов в кодировке CP-1251. Для того чтобы можно было работать с документами в кодировке CP-866, введено автоматическое определение типа кодировки. При необходимости файл документа после считывания в память перекодируется в CP-1251. Процедура выделения из текста слов, чисел и знаков препинания совершенно очевидна. Как и [2], найденные лексемы помещаются в выходной динамический массив. Однако теперь, в отличие от [2], лексический анализатор содержит эвристический механизм определения границ предложения, и результатами лексического анализа является не только массив лексем, но и указатели на начало и конец текущего предложения в тексте. Первой стадией является определение начала предложения. Большинство документов, с которыми должна работать программа, содержит заглавие, набранное прописными буквами; напротив, собственно текст пишется прописными буквами крайне редко. Заглавия документа и его разделов, как правило, не являются синтаксически законченными предложениями, поэтому при создании БСС их следует пропускать. Таким образом, анализатор пытается найти хотя бы два последовательных слова, состоящих не только из прописных букв. Если такая пара слов найдена, она считается началом предложения. Тем не менее одного этого условия недостаточно для надежного различения заголовка и собственно текста. Часто заголовок также набирается по обычным правилам: первое слово с прописной буквы, а остальные буквы строчные. Чтобы распознавать такие заголовки, вводится еще одна проверка: текст анализируемого предложения не должен содержать “пустых” строк, т. е. двух или более символов перевода строки подряд — ведь в подавляющем большинстве случаев заглавие документа или раздела отделяется от текста хотя бы одной пустой строкой. Таким образом, если при сканировании предложения анализатор встречает подряд два символа перевода строки, он считает данное предложение заголовком; при этом динамический массив лексем полностью очищается и анализ предложения начинается заново с текущей позиции. Найти конец предложения в тексте тоже не так просто, как может показаться. Восклицательный или вопросительный знак наверняка означают конец предложения, но вот точка может стоять и после сокращения, и в середине десятичной дроби. Например, в следующем фрагменте: В 1997 г. доход по вкладу составлял 7.5 процентов. точка встречается трижды, и только в третьем случае она означает конец предложения. Для точного ответа на вопрос, находится ли данная точка в конце предложения, потребуется выполнить синтаксический (и даже, возможно, семантический) анализ всего фрагмента. Но ведь решение должно быть принято на этапе лексического анализа! Поэтому в анализаторе введена простейшая проверка: лексема, стоящая непосредственно перед точкой, должна быть грамматически правильным словом и содержать хотя бы одну гласную. Такой проверкой удается отсечь многие сокращения, употребляемые с точкой на конце: см. , г. , р. , и т.д. , пп., др. Разумеется, такая проверка не гарантирует правильность результата. С одной стороны, сокращение или число с точкой могут действительно стоять в конце предложения, а с другой — некоторые сокращения (например: руб., проч.) эту проверку проходят. Тем не менее опыт работы с документами подтвердил эффективность такой проверки. Работающий по описанным правилам анализатор был испытан на документе с текстом Конституции РФ. По результатам испытаний было замечено, что в текст предложения попадают стандартные заголовки разделов, оканчивающиеся точкой: Статья 58. Тогда к анализатору было добавлено еще одно эвристическое правило: предложение не может начинаться со слова “статья”, “глава”, “раздел”, “параграф”, если после него следуют число и знак препинания (не обязательно точка). Как уже говорилось, лексический анализатор работает по простым эвристическим правилам, не всегда обеспечивающим правильность определения границ предложения. Поэтому результат его работы (выделенное из документа предложение) передается пользователю для контроля и, при необходимости, исправления (см. раздел “Интерфейс пользователя и работа с программой”). Морфологический анализ с использованием стандартной СУБД Подробное описание методов представления морфологической информации и соответствующих алгоритмов морфологического анализа дано в [2]. Как и ранее, здесь используется процедурная схема морфологического словаря и анализа. При такой схеме каждое слово представляется в виде суммы неизменяемой основы и переменного аффикса (включающего окончание и, возможно, суффикс слова). Морфологический словарь построен так, что основы и аффиксы хранятся отдельно, и каждая основа содержит ссылку на соответствующий тип аффиксов. Общий алгоритм морфологического анализа можно представить следующей блок-схемой:
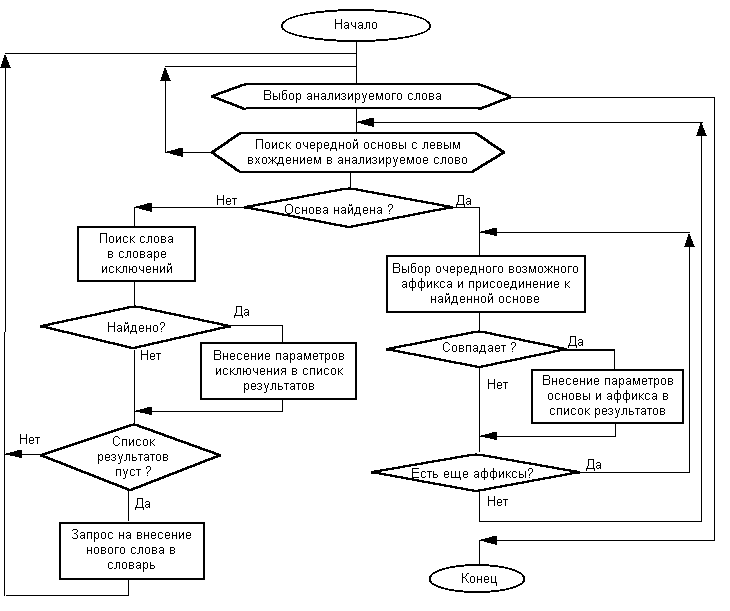
Три ключевых момента отличают реализацию морфологического анализа в программе TreeBanker от его реализации в работе авторов [2] :
Таким образом, было решено реализовать морфологический словарь в виде набора таблиц Paradox 5.0. При этом отпала необходимость в “самодельных” поисковых механизмах: средства поиска записей в СУБД оказались вполне подходящими для реализации морфологического анализа (подробнее об этом речь пойдет ниже). При реализации функции поиска в таблице основ были испытаны два способа: непосредственный поиск средствами BDE (функции FindKey, SetRange и др.) и поиск средствами SQL-запросов (через компонент TQuery). Наиболее важным критерием здесь является быстродействие. Результаты экспериментов показали, что оптимально построенный SQL-запрос обеспечивает поиск примерно вдвое быстрее, чем функция FindKey. Применение же функции SetRange увеличивает время поиска еще в 3—4 раза, что обусловлено, вероятно, переиндексацией всей таблицы основ. Таким образом, для реализации морфологического анализа был выбран способ SQL-запросов. Рассмотрим различные способы построения такого запроса. Наиболее важным фактором здесь является структура таблицы аффиксов. Возможны два варианта структуры: “горизонтальный” (при котором одна запись содержит сразу все формы данного аффикса) и “вертикальный” (на каждую форму каждого аффикса отводится отдельная запись). Второй вариант лучше вписывается в традиционную технологию работы с БД, однако первый оказывается гораздо удобнее для редактирования и пополнения морфологического словаря. Это показал еще опыт работы с проектом [2], в котором использовался прообраз “горизонтальной” структуры. В результате для данного проекта был выбран именно “горизонтальный” вариант. По схеме “основа+аффикс=слово” требуется выбрать все записи, в которых поле “основа” совпадает с началом анализируемого слова. Если бы таблица аффиксов была организована по “вертикальной” схеме, запрос можно было бы построить так: select * from MORPHO, ENDINGS where где :KeyWord — анализируемое слово, MORPHO — таблица основ, ENDINGS — таблица аффиксов, EndID — тип аффикса, Part — часть речи, TheWord — собственно текст. При этом весь анализ выполняется одним запросом, но поиск получается двухмерным и, как следствие, очень медленным. Для “горизонтальной” таблицы аффиксов одного запроса оказывается недостаточно, или его приходится делать очень сложным. Поэтому анализ проводится в две фазы: 1) выбор всех подходящих основ; и 2) проверка всех типов аффикса, соответствующих выбранным основам. Как средствами SQL выбрать все строки, с которых может начинаться :KeyWord? Пусть анализируется слово “авторский”. Оператор LIKE здесь не работает. Запрос select * from MORPHO where решает как раз обратную задачу, а поменять местами операнды TheWord и ‘АВТОРСКИЙ’ не удается! Тем не менее решение было найдено очень простое: select * from MORPHO where Нетрудно убедиться самостоятельно, что этот запрос отбирает те и только те основы, которые являются началом слова :KeyWord. Заметим только, что ни одно слово в русском языке не имеет окончания, которое по алфавиту следовало бы после цепочки ‘ЯЯЯ’. Представленный выше запрос имеет явный недостаток: вне зависимости от анализируемого слова он выбирает все слова-исключения (у них основы пустые). Чтобы увеличить скорость анализа, можно заимствовать идею из проекта [2]: сначала искать только среди обычных слов, а если анализ окажется безрезультатным — вернуться и выполнить поиск среди исключений. Для поиска среди обычных слов к запросу добавляется строчка and (TheWord >= ‘А’), а для выборки всех исключений вторая и третья строки заменяются на (TheWord = ‘’). После того как подходящие основы выбраны, следует вторая стадия анализа — поиск нужного типа аффиксов в таблице ENDINGS по ключам EndID и Part, а затем проверка всех аффиксов данного типа на совпадение с оставшейся частью слова :KeyWord. Эта стадия реализована уже с помощью функции FindKey([Part, EndID]) — опыт показал, что в этом случае она работает несколько быстрее аналогичного SQL-запроса. Синтаксический анализ на базе набора правил Программа TreeBanker выполняет синтаксический анализ предложения в полуавтоматическом режиме. Выбор группируемых узлов производит оператор, а программа самостоятельно определяет тип нового узла и положение главного слова в нем. При таком разделении труда задача синтаксического анализа с точки зрения программы существенно упрощается, поскольку наиболее сложную часть — задание последовательности группировки узлов — берет на себя пользователь. В “облегченных” условиях оказалось удобным задействовать код синтаксического анализатора из [2]. Для упрощения структуры программы объектно-ориентированный набор правил был переписан в виде нескольких отдельных функций, каждая из которых проверяет множество различных вариантов формирования нового синтаксического узла. Сама процедура анализа теперь выполняется так:
“Нулевой” результат может прежде всего означать, что выбранные пользователем узлы не образуют синтаксическую составляющую — другими словами, что пользователь ошибся при выборе. Тем не менее, чтобы дать пользователю возможность формировать узлы новых типов или нестандартных конфигураций, программа в таких случаях предлагает ему ввести тип узла и выбрать главное слово вручную. Типы синтаксических узлов вместе с их описаниями хранятся в отдельной таблице базы данных — синтаксическом словаре. При необходимости пользователь может добавлять в эта таблицу новые записи. Интерфейс пользователя и работа с программой Программа управляется с помощью меню стандартного вида и нескольких “горячих клавиш”. Главное меню программы содержит следующие команды: Файл \ Открыть документ Выбирает текстовый файл, предложения из которого предназначаются для добавления в набор примеров. Файл \ Редактировать БСС Вызывает на экран окно редактирования уже существующего набора примеров. Файл \ Выход Завершает работу с программой. Словарь \ Морфологический Вызывает на экран окно для редактирования и пополнения морфологического словаря. Словарь \ Синтаксический Вызывает на экран окно для редактирования и пополнения синтаксического словаря. Словарь \ Семантический \ Общий Вызывает на экран окно для редактирования и пополнения таблицы семантических объектов. Словарь \ Семантический \ Модели управления Вызывает на экран окно для редактирования и пополнения таблицы моделей управления (элементарных и групповых). Словарь \ Семантический \ Семантические роли Вызывает на экран окно для редактирования и пополнения таблицы семантических ролей. Помощь \ О программе Выводит информацию о названии и версии программы. Типичная последовательность действий пользователя при работе с программой выглядит следующим образом:
Это меню содержит два пункта: “Создать узел” и “Удалить узел”. В зависимости от того, сколько и каких узлов выделено на экране, в меню будет доступен один из этих пунктов или недоступны оба. Если же синтаксический анализатор не смог подобрать адекватную синтаксическую интерпретацию выбранным узлам, на экран выводится окно для ручного выбора типа узла и главного слова в нем. Это окно содержит два списка: в левом — перечень выделенных узлов (среди них пользователь должен указать главный узел), в правом — список известных системе типов узла. Если требуемый тип узла отсутствует в списке, пользователь может добавить его самостоятельно. В отличие от описанного выше режима создания БСС, режим редактирования сразу переходит к страничке синтаксического анализа, где отображается текущая синтаксическая структура из файла БСС. В этом режиме кнопки “Дальше” и “Назад” вызывают перемещение, соответственно, вперед и назад по файлу БСС. Форматы данных Представление морфологической информации Очевидно, после выполнения морфологического анализа его результаты необходимо сохранить во внутренних структурах программы. В противном случае работа программы сильно замедлится из-за постоянных обращений к ядру BDE за данными из таблиц БД. Структура таблиц словарной базы данных уже была описана в разделе “Словарная подсистема ”. Для внутреннего представления записей из таблицы основ в программе используются структуры TBaseRec следующего формата:
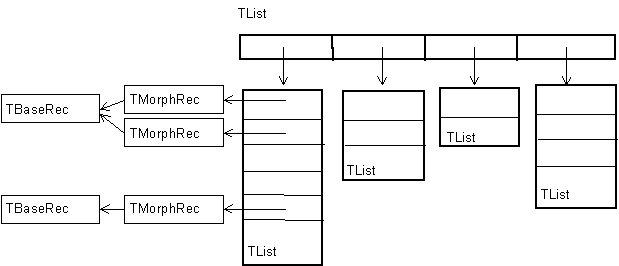
Для внутреннего представления всей морфологической информации, извлеченной из словаря по результатам морфологического анализа, в программе используются структуры TMorphRec следующего формата:
Вся совокупность результатов морфологического анализа представляется в виде динамического массива TList. Число его элементов равно числу лексем в предложении. Элементами массива являются другие массивы TList, каждый из которых хранит все возможные интерпретации своей лексемы в виде структур TMorphRec. Таким образом, общая структура данных, представляющая результат морфологического анализа, имеет вид:
Представление синтаксической информации Основной единицей синтаксической структуры является “узел”. Синтаксический узел содержит морфологические параметры (источником которых в конечном счете выступают результаты морфологического анализа), а также упорядоченный набор ссылок на дочерние узлы. Для представления синтаксического узла в программе используются структуры TSyntNode следующего формата:
Синтаксическая структура предложения представляется в виде динамического массива TList, содержащего структуры TSyntNode с соответствующими значениями полей NodeID, ParentID и Children. Массив Children содержит не указатели, а идентификаторы дочерних узлов, поскольку структуры TSyntNode должны сохраняться в файле и затем считываться из него. Нетрудно заметить, что структура TSyntNode дублирует все поля, которые использовались в структурах TBaseRec и TMorphRec. Это было сделано для того, чтобы массив структур TSyntNode был бы достаточен для представления всей информации об анализируемом предложении, без использования вспомогательной структуры с морфологической информацией. Ведь на этапе обучения вероятностный анализатор не имеет никакой другой информации, кроме массива структур TSyntNode. Файл БСС Файл, накапливающий разобранные примеры предложений (файл БСС), пополняется всякий раз, когда пользователь сохраняет очередную синтаксическую структуру. Этот файл имеет имя treebank.dat. Новое разобранное предложение просто дописывается в конец файла. Каждый узел сохраняется в виде записи следующего формата:
Все синтаксическое дерево предложения — массив TList со структурами TSyntNode — записывается в виде последовательности таких записей. Число их равняется числу узлов дерева плюс еще один фиктивный “корневой” узел, который записывается первым. Этот узел предусмотрен на случай, когда по каким-либо причинам сформированная синтаксическая структура не является односвязным деревом. Тогда “корневой” узел включает в себя отдельные связные поддеревья. Дальнейшее развитие программы Хотя уже в текущей версии программа TreeBanker является работоспособным инструментом для создания вероятностного синтаксического анализатора, имеет смысл несколько улучшить ее работу, прежде чем переходить непосредственно к созданию банка синтаксических структур. Во-первых, морфологический анализатор следует дополнить своего рода “препроцессором”, который уменьшает число возможных вариантов морфологического разбора на основе контекстной информации. Например, у стоящих последовательно прилагательного и существительного можно оставлять только формы, совпадающие по роду, числу и падежу; у существительного, стоящего после предлога, оставлять только падежные формы, допускаемые предлогом, и т. д. Во-вторых, во время опытной эксплуатации программы (например, первых 200 предложений) необходимо фиксировать все типы синтаксических узлов, не распознанные анализатором. После этого в код программы следует добавить соответствующие правила, чтобы в дальнейшем такие узлы распознавались автоматически. В-третьих, при опытной эксплуатации необходимо следить за правильностью лексического анализа, а именно за правильностью определения границ предложений. Возможно, потребуется добавить несколько дополнительных правил для этого алгоритма. И наконец, следующим и наиболее крупным этапом настоящего проекта станет программная реализация ядра вероятностного анализатора, в том числе всех алгоритмов, описанных в разделах вероятностного анализа. Заключение Подведем краткие итоги проделанной работы. Во-первых, Разработан вероятностный алгоритм синтаксического анализа, учитывающий специфику морфологии и синтаксиса русского языка. Во-вторых, алгоритм дополнен этапом предварительного морфологического разбора, реализованного посредством поиска в морфологическом словаре. Это позволило значительно сократить число перебираемых при анализе вариантов, что при реализации алгоритма должно привести к соответствующему росту скорости анализа. В-третьих, реализовано инструментальное средство, позволяющее решить проблему отсутствия общедоступных БСС на русском языке. Опытная эксплуатация разработанной в рамках данного проекта программы TreeBanker показала ее высокую эффективность как инструмента для подготовки БСС. В-четвертых, спроектирована структура программного комплекса, в котором будет реализован алгоритм анализа. Определены пути его интеграции в проект “Минерва”. В-пятых, осуществлен перенос морфологического словаря, разработанного в [2], в стандартную базу данных. Это, с одной стороны, позволило снять ограничения на объем словаря, а с другой — сделать словарь открытым для других приложений. В-шестых, реализован простой, но достаточно эффективный алгоритм распознавания законченных предложений в тексте. Алгоритм использован в программе TreeBanker. Литература
|

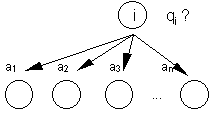
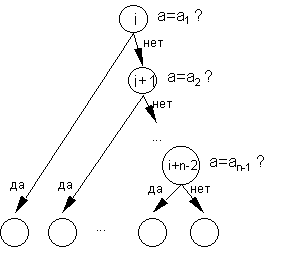


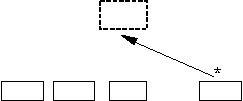
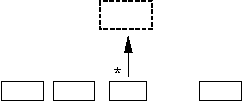
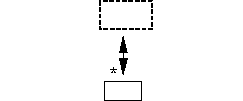
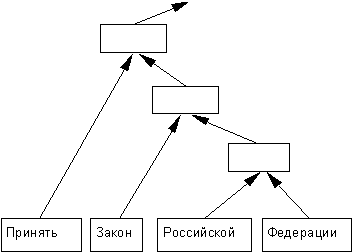
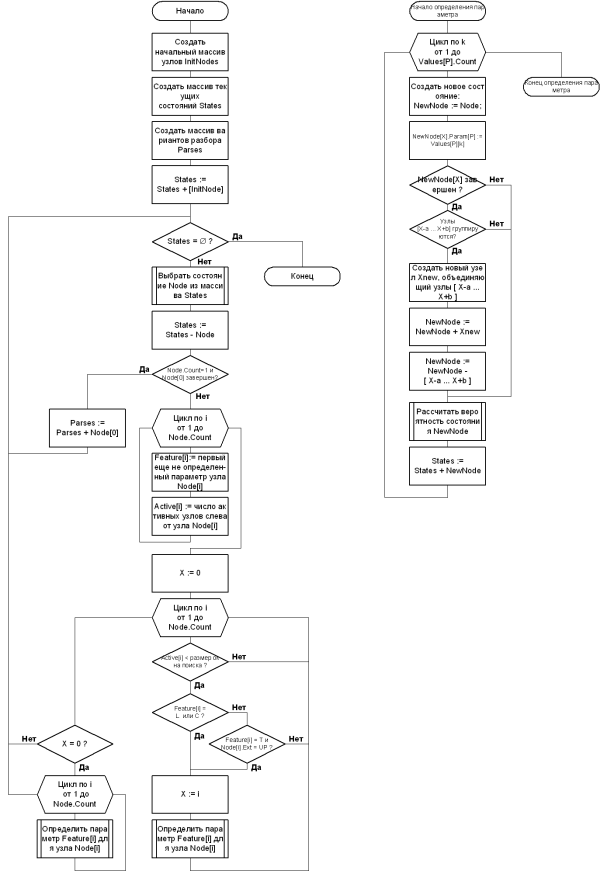
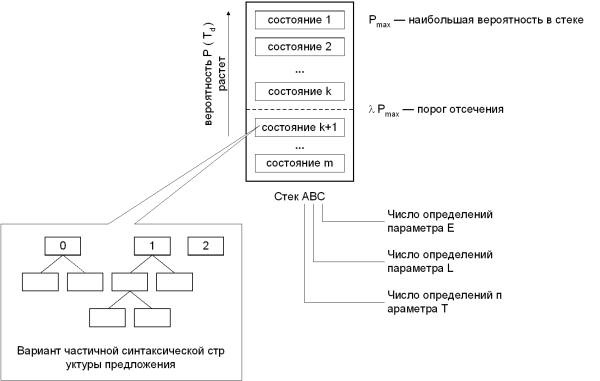
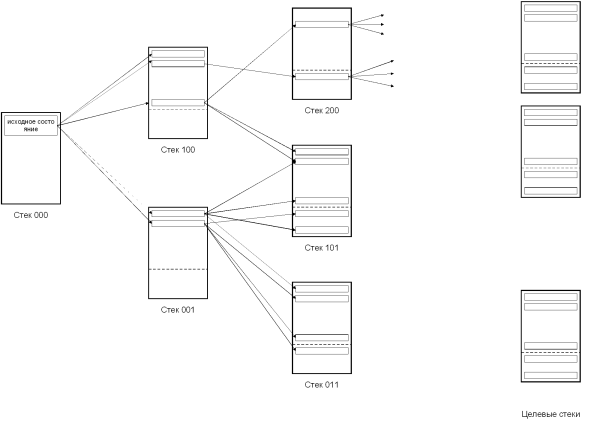 Поскольку в исходном состоянии значения присваиваются только параметрам Nt и Ne, то состояния, получаемые из исходного, могут попасть либо в стек 100, либо в стек 001. Состояния, построенные из стека 100, могут попасть в стеки 101, 200 или 110. И т. д.
Поскольку в исходном состоянии значения присваиваются только параметрам Nt и Ne, то состояния, получаемые из исходного, могут попасть либо в стек 100, либо в стек 001. Состояния, построенные из стека 100, могут попасть в стеки 101, 200 или 110. И т. д.