УДК 681.3 Объектно-ориентированная база |

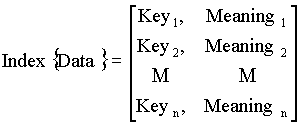 , (1)
, (1)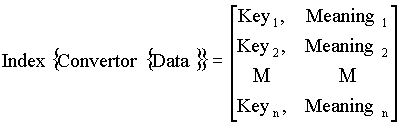 . (2)
. (2)
|
Тип 1 |
Тип 2 |
Тип K |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Общее количество объектов в базе вычисляется очень просто:
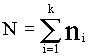 . (3)
. (3)
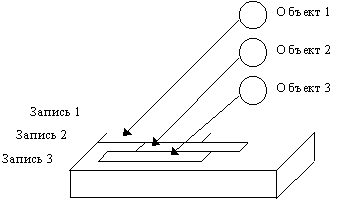
Можно ввести понятие “дескрипторной структуры” объектной СУБД ODB-Jupiter, которая задается таблицей размерностью M x K, где
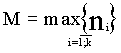 , (4)
, (4)
K - количество типов в текущий момент в базе данных. Элементы таблицы - уникальные идентификаторы соответствующих объектов в БД.
Таким образом, на этом уровне известно с какими типами мы имеем дело, но нет средств для построения логики взаимодействия объектов.
1.3.3 Объектный уровень
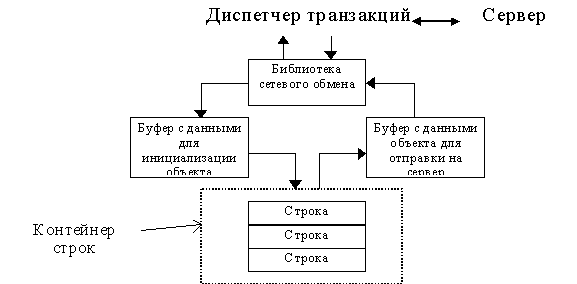
На этом уровне присутствуют объекты базы данных, которые взаимодействуют по определенным правилам. Здесь происходит процесс приемки сообщений по сети от сервера, их расшифровка, создание объектов и структур, необходимых для интерпретации данных в сообщении. Обратное действие - реакция на команду клиента, после которой извлекается информация из объектов и структур, указанных в команде. Информация укладывается в линейный буфер и в таком виде отправляется на сервер. Таково в общих чертах назначение объектного уровня. С одной стороны, он соприкасается с низкоуровневым интерфейсом сети (в случае сервера - с библиотеками управления записями и индексами), а с другой сам предоставляет интерфейс для реализации более высоких уровней и интерфейса с пользователем.
В иерархии классов объектного уровня присутствует множество узлов. Наиболее значимые представлены в таблице 1.
|
TNetClient |
Объект ведает установлением и поддержанием сетевого соединения с сервером. Обеспечивает отправку и прием сообщений по сети. По информации, сопутствующей сообщению, определяет его адресат и выполняет диспетчеризацию. |
|
TClientDatabase |
Объект, реализующий на клиентском месте функции управления базой данных. Большая часть операций, выполняемых TClientDatabase, скрыта от верхних уровней. Ими пользуются объекты-потомки TOdbObject для обмена данными с базой данных. Интерфейс объекта обеспечивает явную блокировку базы данных - до явной отмены блокировки база остается в монопольном владении клиента, блокировавшего ее. |
|
TOdbManager |
Вмещает в себя: Базу данных классов Базу данных индексаторов Список активных баз Фабрику объектов Объект-менеджер - это, по существу, информационный центр объектного уровня. Он ведет информационную базу классов, от которых можно создать экземпляры объектов, сохраняемые в базе данных. Он же может выступать в качестве фабрики объектов и порождать объекты по требованию. Через менеджер можно получить доступ к активным объектам TClientDatabase, представляющих собой проекции баз данных сервера на клиентское место. |
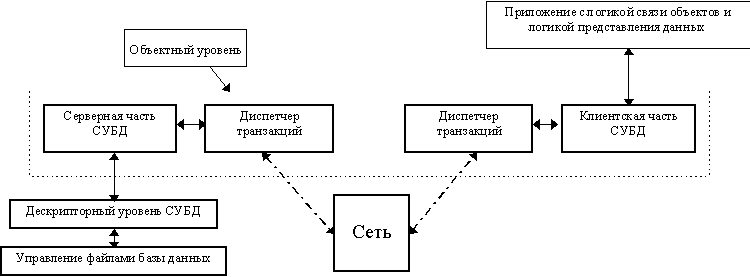
На Рис. 6 приводится обобщенная схема объектного уровня СУБД ODB-Jupiter.
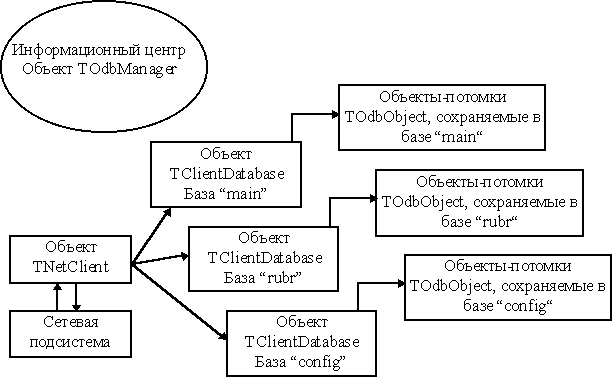
Рис. 6. Декомпозиция объектного уровня.
Когда клиент устанавливает соединение с сервером, создается один объект класса TNetClient, который обеспечивает поддержание канала связи с клиентской стороны. В одном сеансе связи, как правило, приложение работает с несколькими базами данных. На рис изображен случай когда прикладная программа работает с объектами, находящимися в трех различных базах данных. Имена баз - “main”, “rubr”, “config”. Каждый объект, обладающий свойством обмена с базой данных, знает имя сервера и имя той базы данных, куда он будет отправлен. Каждый объект TClientDatabase поддерживает список объектов-потомков TOdbObject, связанных с данной базой.
1.3.4 Уровень приложений
Объектный уровень, описанный выше, предоставляет обширный программный интерфейс объектно-ориентированной СУБД. Программный интерфейс СУБД собран в одной динамически загружаемой библиотеке. На уровне приложений функционируют библиотеки высокого уровня и прикладные программы, которые связывают данные объектов определенной логикой и осуществляют визуализацию данных из базы, интерактивное или иное взаимодействие с пользователем. Разработчик приложения никак не ограничивается количеством используемых узлов сети и баз данных. Как правило, разработчик-программист создает ряд классов, которые планируется сохраняться в базе данных. Подробно о том как создать свой класс см. пункт 1.2.2. Здесь напомним, что надо перекрыть и реализовать ряд методов класса TOdbObject. Имя сервера и имя базы данных можно задавать, используя словарь объектов БД, если пользователь работает с объектами-документами. В ином случае надо явно указывать имена посредством обращений к соответствующим методам объекта.
1.3.5 Особенности реализации
Текущая версия объектно-ориентированной базы данных ODB-Jupiter - и клиент и сервер - функционирует в операционной системе Windows. Приложения, разработанные для нашей СУБД, следовательно, также работают в окружении Windows. Windows привносит некоторые особенности в реализацию СУБД и ее интерфейса.
Во-первых, у сервера баз данных реализован удобный Windows интерфейс, понятный пользователю. Используя систему меню, администратор базы данных создает, конфигурирует, удаляет базы данных на сервере.
Во-вторых, используется предоставляемая Windows возможность оформлять библиотеки в виде DLL (динамически загружаемых библиотек).
В-третьих, сетевой обмен в ODB-Jupiter происходит в пределах локальной вычислительной сети Windows или средствами удаленного доступа Windows 95. Таким образом, допускается одновременная работа с базой данных нескольких клиентов. Так как сеть Windows одноранговая, то допускается работа нескольких серверов ODB-Jupiter. Это открывает широкие возможности для конфигурирования информационной системы на основе ODB-Jupiter и распределения нагрузки между рабочими станциями.
В-четвертых, поскольку база данных ODB-Jupiter работает в среде Windows, очень важным представляется поддержка протокола OLE 2.0 (Object Linking and Embedding - вставка и связывание объектов). Напомним, что поддержка протокола OLE обеспечивает интеграцию с Windows-приложениями. Клиентская часть СУБД предоставляет интерфейс, который дает возможность сохранять в базе данных OLE-объекты. Разработчик прикладной программы, к тому же, получает инструмент, облегчающий встраивание в свои программы механизма OLE.
1.4 Декомпозиция СУБД
На Рис. 7 представлена внутренняя структура СУБД ODB-Jupiter. Ниже следует краткое описание основных блоков этой структуры.
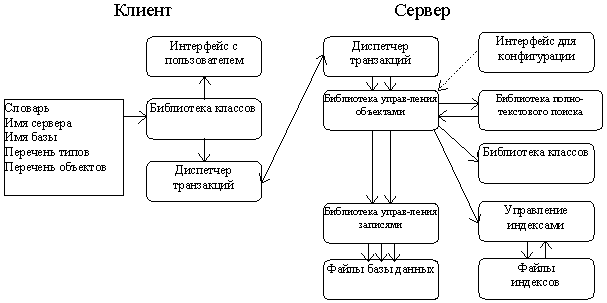
Рис. 7. Элементная схема СУБД ODB-Jupiter.
Файлы базы данных. Представляют собой массив страниц фиксированной длины. Часть начальных страниц объявляется служебными. В них хранится информация для обеспечения структурной целостности базы данных: количество страниц в файле, количество занятых и свободных страниц, количество объектов в базе, номер первой и последней свободной страницы и т.д. каждый объект занимает одну и более страниц. Непосредственно перед данными объекта располагается таблица размещения объекта в базе. Это просто массив номеров страниц, в которых сохранены данные объекта. Естественно, во время занесения объекта в базу ему присваивается уникальный идентификатор, который остаётся неизменным вплоть до удаления объекта из базы данных.
Файлы индексов. Ряд объектов могут быть проиндексированы с целью быстрого доступа. В СУБД для этого есть специальный набор классов - индексаторов. В файл индексов попадают поисковые ключи в виде пары - (“ключ”, “значение ключа”). Значение ключа для всех типов, кроме текста, это идентификатор объекта, в котором находится ключ. То есть, найдя ключ, удовлетворяющий поисковому запросу, легко извлечь из базы сам объект. Случай текста сложнее. Значение ключа для текста тоже пара - (“идентификатор объекта”, “порядковый номер ключа в тексте”). То есть, реализуется на уровне индексов поддержка полнотекстового поиска.
Библиотека управления записями. Имеет дело с набором записей в базе данных. Реализует добавление, замещение и удаление записей в базе данных. После успешной операции изменения файла база данных корректирует информацию в служебном разделе файла базы. Если результат операции не удачен, то происходит откат транзакции и база возвращается в корректное состояние. Рассмотрим более пристально процесс добавления записи в базу данных. Исходные данные - указатель на буфер с данными объекта и длина буфера.
- начало транзакции
- вычисление количества страниц N для размера объекта
- чтение из блока служебной информации номера первой свободной страницы
- формирование массива P страниц размером N, причём сперва страницы берутся из числа свободных, а затем, по мере необходимости, увеличивается файл базы
- запись массива P (иначе, таблицы размещения объекта в первой свободной странице)
- последовательная запись данных в страницы из массива P
- присвоение объекту идентификатора - номер первой страницы
- модификация служебной информации
- конец транзакции
Библиотека управления индексами. Поддерживает структуру поисковых ключей в виде B+ - дерева (Рис. 8). Обеспечивает доступ к ключам в именованных индексах. БУИ позволяет хранить в одном файле индекса до 256 индексных структур. Каждый индекс характеризуется именем, типом ключа и типом значения. Возможные операции: добавление ключа, удаление ключа, поиск ключа по совпадению, по условию, по основе (с маскированием окончания). Все действия по модификации индексного файла происходят в режиме транзакций.
Рис. 8. Структура индекса в СУБД ODB-Jupiter.
Библиотека управления объектами. В паре с библиотекой классов является ядром объектной СУБД. Выполняет следующие функции:
- создание объекта в оперативной памяти по буферизованным данным
- модификация индексных данных объекта
- выполнение поиска
- получение списка поисковых ключей
- захват/освобождение полей документов, недопущение повторных захватов.
Библиотека классов (клиента и сервера). Схему иерархии см. сопоставление с Манифестом. По существу это - скелет схемы базы данных. Представляет собой набор классов, которые могут присутствовать в базе. Предоставляется механизм, по которому пользователь может добавить новый класс. Каждый класс имеет уникальное символьное имя и функцию, которая создаёт динамический экземпляр объекта. Следует обратить внимание, что в СУБД есть два экземпляра реализации библиотеки классов. Такая избыточность даёт возможность строить действительно распределённые приложения. Разработчик сам расставляет акценты, перераспределяя задачи между сервером и клиентом.
|
Данные: |
Строка [ ] |
Индексаторы: |
|
|
Текст [ ] |
|
||
|
Целое |
Число [ ] |
|
|
|
Дата [ ] |
|
||
|
Вещественное |
Число [ ] |
|
Диспетчер транзакций. Это небольшой модуль, принимающий сообщения и данные от сетевого уровня. Клиент и сервер сперва устанавливают сетевое соединение, которое обрывается только в случае команды одной из сторон. Одна из важнейших задач диспетчера - идентифицировать адресат сообщения. Рассмотрим сперва серверный диспетчер. Поскольку один сервер обслуживает несколько баз данных, запросы приходят к различным базам. С каждой базой сервер взаимодействует посредством объектного интерфейса.
1.5 Сравнительный анализ
Мы считаем полезным соотнести архитектуру и принципы разработки с пунктами “Манифеста объектно-ориентированных баз данных” [5]. Это позволяет увидеть достоинства и недостатки и, что наиболее важно, дает точку отсчета для определения путей дальнейшего развития.
1. Сложные объекты.
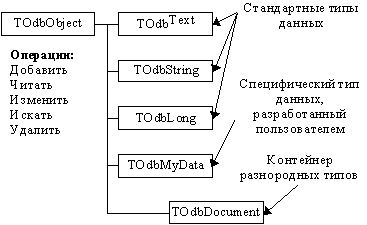
ODB-Jupiter поддерживает “традиционные” типы данных: целое число, вещественное число, дата, строка символов, время, номер телефона. Из сложные типов данных изначально встроены текст и OLE-объекты. Благодаря объектному подходу легко решается проблема наращивания множества типов. Для этого есть два пути. Во-первых, существует особый тип документ-контейнер, который содержит в себе объекты простых типов данных или документы-контейнеры. В терминах СУБД ODB-Jupiter они называются полями документа. Вторая возможность неограниченного наращивания мощности типов достигается через отношение владения. Любые два объекта могут быть объединены отношением владелец-подчиненный. Подчиненный объект перенимает у владельца его идентификатор и перестает быть независимым. Его данные и сохраняются в базе данных как часть данных владельца. Поисковые ключи попадают в индексы, также связанные с объектом-владельцем.
2 .Идентифицируемость.
Каждый объект при сохранении в базе данных получает уникальный идентификатор, по которому впоследствии возможно с ним связаться. Ссылки на другие объекты обозначаются их идентификаторами. Зная идентификатор, всегда можно извлечь объект из базы данных. Как упоминалось выше, значительно упрощается доступ к объекту после поиска поскольку к каждому ключу приписаны все идентификаторы объектов, которые его содержат.
3. Инкапсуляция данных и процедур.
СУБД ODB-Jupiter реализована на языке C++. Как известно, C++ реализует инкапсуляцию через ограничение доступа к данным и предоставлением программного интерфейса для манипуляций с данными.
4. Поддержка типов и классов
Поскольку язык реализации и расширения СУБД - C++, следовательно поддерживается концепция классов, причем допускается множественное наследование.
5. Иерархия типов и классов
Иерархия классов представлена на Рис. 2. Понятия типа и класса в ODB-Jupiter не тождественны. Напомним, что пользователь может двояко расширять набор типов нашей СУБД. Во-первых, посредством создания нового класса-потомка одного из классов объектной иерархии. Во-вторых, пользователь может модифицировать объект-контейнер TOdbDocument, задавая определенный набор полей и получает при этом новый тип документа. Оба пути создания новых типов совершенно равноправны.
6. Перекрытие, перегрузка и позднее связывание
В этом пункте ограничимся ссылкой на руководство по языку программирования C++ [4].
7. Вычислительная полнота
Можно целиком сослаться на C++. Вопрос, таким образом, в вычислительной полноте языка C++. Хотя вопрос представляется вполне очевидным, скажем несколько слов по этому поводу. Язык C++ поддерживает следующие парадигмы программирования:
создание абстрактных типов данных
модель процедурного и модульного программирования
модель объектно-ориентированного программирования
набор стандартных библиотек функций, классов и шаблонов
средства для доступа к сервисам операционной системы.
Таким образом, язык C++ обеспечивает разработчика полнотой средств для создания прикладных программ, реализующих самые сложные задачи.
8. Расширяемость
Расширяемость реализуется двумя способами.
Во-первых, стандартным для объектного программирования образом: наследованием новых классов от неких базовых классов, имеющих свойства взаимодействия с базой данных. Причем можно наследовать новый класс от класса-объекта БД TOdbObject, полностью реализуя функциональность нового типа данных. Иной способ - наследование от класса с готовым наполнением, например, от TOdbString, TOdbText и создание нового поведения класса.
Во-вторых, созданием нового типа - документа. Пользователь определяет набор полей документа и получает, таким образом, новый тип данных, который может храниться в базе данных.
Подробнее вопросы расширяемости рассматривались в пункте 1.2.2.
9. Стабильность
Конечно же, поддерживается долговременное хранение данных объектов. В базе данных сохраняются атрибуты объектов вместе с информацией, необходимой для восстановления полноценного объекта в оперативной памяти.
10. Управление вторичной памятью
В ODB-Jupiter встроен мощный механизм для управления массивами информации во вторичной памяти. Этой цели, как упоминалось выше, служит целый уровень СУБД. Если в атрибутах объекта указано, что он поисковый, то система генерирует специальный поисковый индекс(индексы), связанный(связанные) с данными объекта. Конечно же, механизмы переноса объектов в базу данных и формирование индексов “невидимы” для пользователя-программиста.
11. Параллелизм
ODB-Jupiter изначально разрабатывалась с целью использования в сети. Система построена по принципу клиент/сервер. Все рутинные операции по манипуляции файлами баз данных, по переиндексации данных выполняет сервер. Программа-клиент служит для визуализации данных и для удобной работы пользователя. Имеется поддержка групповой работы с базами данных, блокировки БД, слежение за одновременным доступом к одному объекту.
12. Восстановление
Устойчивость к сбоям аппаратуры и операционной системы обеспечивается работой механизма транзакций. Если выполнение операции не завершилось, то СУБД переводит файлы базы данных в корректное состояние, которое было до начала операции.
Дополнительно возможна операция восстановления индексов в случае сбоев диска.
13. Средства обеспечения незапланированных запросов
Имеется простой язык, на котором формируются поисковые запросы к БД. Однако для эффективной работы конечного пользователя следует реализовывать механизм визуализации, например, в виде запроса по форме. Более того, в СУБД встроен алгоритм обработки полнотекстовых поисковых запросов, задаваемых на естественном языке.
1.6 Разработка приложений
Разработка прикладной программы, использующей возможности, заложенные в ODB-Jupiter, включает в себя следующие шаги:
- Проектирование структуры приложения - состав модулей и их взаимодействие.
- Проектирование и спецификация классов.
- Разработчики реализуют программный код тела класса с использованием любой среды разработки, генерирующей выполняемые модули для среды Windows.
- Создание физических баз данных на сервере.
- Отладка приложения с использованием средств отладки той же среды.
В качестве примера приложения, использующего СУБД ODB-Jupiter можно привести полнотекстовую информационно-поисковую систему (ИПС) ODB-Text версии 2.0 [6]. Вопросы использования объектного подхода к созданию информационных систем различного назначения рассмотрены в [7,9].
ИПС “ODB-Text”
Центральное понятие в ИПС “ODB-Text” - это документ. Документ в системе - это не файл, а именно документ в базе данных, снабженный регистрационной карточкой. Сразу после установки и ознакомления с основными возможностями системы пользователь формирует виды документации, с которыми будет работать. Для конкретного типа документа он создает регистрационную форму, в которой указывается какая информация будет сопутствовать каждому экземпляру документа. Форма представляет собой набор полей различных типов. Например, для договора наверняка будут указаны название организации-контрагента, дата подписания, общая сумма, количество и сроки выполнения этапов и т.п. Подчеркнем, что каждый пользователь может сформировать наиболее подходящий для себя и для своей фирмы вариант. В дальнейшем в регистрационной форме можно легко переименовать, добавить, удалить поля. После перемен система будет отображать новые поля, сохраняя содержимое старых, в том числе переименованных.
Новые документы вводятся во встроенном редакторе документов. Если какие-то документы есть в виде дискового файла, то их можно просто загрузить в базу данных. Главная особенность “ODB-Text” версии 2.0 - поддержка протокола OLE2. Напомним, что механизм Object Linking and Embedding (Вставка и Связывание Объектов) обеспечивает интеграцию объектов OLE-сервера в документы других программ. Программа-клиент ”ODB-Text” позволяет сохранять в базе данных документы, в которые вставлены объекты OLE. Документы MS Word, таблицы MS Excel, презентации Power Point, иллюстрации, подготовленные в программах CorelDRAW!, Adobe Photoshop, чертежи AutoCAD for Windows - вот далеко не полный перечень объектов, которые может хранить база данных “ODB-Text”. Пользователь просто переносит документацию, подготовленную в различных программах, в нашу базу данных.
Документы заносятся в базу документов офиса с тем, чтобы их впоследствии можно было быстро найти, просмотреть и изменить. Так, например, целесообразно вынести существенную информацию из текста в регистрационную форму. Обработанные таким образом документы гораздо быстрее воспринимаются. Редактор, уже упоминавшийся выше, представляет собой инструмент формирования дополнительной информации о документе - смысловых понятий, оглавления, гипертекстовых ссылок на другие документы или на строки в тексте этого же документа. После разметки информация отображается непосредственно в тексте и для удобства пользователя может быть выведена в отдельных списках. Таким образом, изначальный “бумажный” документ превращается в своего электронного двойника, с которым гораздо удобнее и проще работать. Время, потраченное на обработку текста, расстановку ссылок, оглавления, выделение понятий с лихвой окупится впоследствии удобством работы с документом. Как и любая ИПС, “ODB-Text” предлагает каталог-рубрикатор, куда можно записать названия всех документов в системе, сгруппировав их по специфическим признакам и разнеся по рубрикам.
В системе используются новейшие достижения в технологии поиска. Поиск ведется как по полям регистрационной карточки, так и по тексту документа. Изюминка “ODB-Text” - полнотекстовый поиск и возможность вводить запросы на естественном языке. Пользователю нет нужды вручную конструировать поисковые запросы - достаточно ввести фразу на обычном разговорном языке. Далее система сама интерпретирует запрос, учитывая особенности русского языка и расстояния между словами. Полнотекстовый поиск выполняется с учетом расстояния между словами и с морфологическим разбором. Например, по запросу “авторское право” будут найдены документы, в тексте которых встречается как сочетание слов “авторское право”, так и слова “авторские права”, “авторскому праву”, “авторскими правами” и т.д. Наряду с естественно-языковым, в “ODB-Text” поддерживается более традиционный механизм контекстного поиска с возможностью комбинировать логические сочетания слов в запросе - “И”, “ИЛИ”, маскированием окончаний слов.
С самого начала разработки “ODB-Text” создавался как средство коллективной работы с документами. Когда клиент обращается за документом, ему передается копия документа из информационного хранилища. Запросы от различных клиентов буферизуются, поэтому проблем с необходимостью блокировки записей в базе данных не возникает. Пользователи имеют возможность одновременно работать с одним и тем же документом, причем клиент, который просматривает документ, редактируемый другим человеком, получает все изменения по мере их совершения. Конечно же, отслеживаются попытки удаления документа, который находится в работе. Наконец, когда последний пользователь завершает редактирование, документ сохраняется в базе данных, изменения индексируются и становятся доступными для каждого клиента.
Система спроектирована и реализована с применением технологии объектного программирования. Поскольку программный комплекс реализован для одноранговой сети Windows и Windows 95, на его основе можно строить масштабируемые решения. Например, возможны варианты с несколькими серверами в сети, размещение сервера на любом компьютере. Поскольку в программном комплексе “ODB-Text” используется стандартный для Windows высокоуровневый протокол обмена данными, то система успешно функционирует в сетях различного типа. Удаленный доступ реализуется средствами Microsoft Windows 95. Таким образом, учитывая, что корпорация Microsoft уделяет большое внимание развитию технологий OLE и удаленного доступа в семействе операционных систем Windows, возможности нашего программного комплекса будут расти по мере появления новых версий “Окон”.
Примеры составления программ.
Приведем несколько простых примеров, демонстрирующих различные аспекты разработки приложений, работающих с СУБД “ODB-Jupiter”. Начнем с создания собственного типа данных.
Для примера используем упомянутый в пункте 1.2.2 класс TOdbPascalString, реализующий хранение строк в стиле языка Pascal. Необходимые пояснения вставлены в виде комментария. Объявление класса см. Листинг 1.
class TOdbPascalString: public TOdbString {
/* объявляем атрибут класса, в котором мы будем сохранять указатели
на строки в формате языка Pascal: первый байт - длина строки,
далее строка без завершающего нуля */
char *m_pPascalStrings[256];
public:
/* конструктор нового класса */
TOdbPascalString(TOdbObject *pParent, void *pvInfo):
TOdbString(pParent, void *pvInfo)
{
/* инициализируем массив нулевыми указателями */
dword i = 0;
for( ; i < 256; i++) {
m_pPascalStrings[ i ] = NULL;
}
}
/* статическая функция, которая служит для создания динамического
экземпляра объекта TOdbPascalString */
static TOdbObject* CreateFunc(TOdbObject *pParent, void *pvInfo)
{
return new TOdbPascalString(pParent, pvInfo);
}
/* метод просто возвращает указатель на строку с именем типа */
const char* RunTimeClassName() {return “TOdbPascalString”;}
/* возвращает длину строки номер dwIndex */
dword GetLength(dword dwIndex)
{
/* сперва делаем необходимые проверки */
if(dwIndex < 256 && m_pPascalStrings[dwIndex] != NULL) {
/* возвращает первый байт строки, который содержит длину
строки */
return *(m_pPascalStrings[dwIndex]);
} else
return 0;
}
/* оператор присваивания, который служит для занесения данных в
текущий элемент объекта;
номер текущего элемента содержится в переменной m_dwItem */
TOdbObject& operator = (char HUGE* pData)
{
/* проверим, не выходит ли текущий индекс за предел нашего
массива */
if(m_dwItem < 256) {
/* преобразуем строку из формата C в формат Pascal */
char *pszPascalString = ConvertCtoPascal(pData);
/* и запишем указатель на нее в массив m_pPascalStrings */
m_pPascalStrings[m_dwItem] = pszPascalString;
}
/* в любом случае возвращается адрес объекта */
return *this;
}
/* преобразование данных объекта к “пустому” указателю,
необходимо для работы механизма обмена данными с сервером */
operator void HUGE*()
{
/* проверим, не выходит ли текущий индекс за предел нашего
массива */
if(m_dwItem < 256) {
/* преобразуем строку из формата Pascal в формат C */
char *pszCString =
ConvertPascaltoC(m_pPascalStrings[m_dwItem]);
return pszCString;
} else
return NULL;
}
/* реализует создание поисковых ключей из данных объекта */
bool CreateIndexData()
{
bool succ = true;
/* обрабатываем только те объекты, которые объявлены поисковыми*/
if(IsSetFlags(Flag_Searched)) {
/* обязательно вызываем метод предка */
TOdbObject::CreateIndexData();
/* так как стандартный преобразователь строк понимает данные в
формате объекта-строки, то надо перевести наши “паскалевские”
строки к обычному представлению;
TChaosString - массив строк, который “понимает”
преобразователь строк */
TChaosString *c_strings = new TChaosString();
/* в цикле преобразуем наши строки к представлению C копируем
их в массив c_strings */
dword i = 0;
for( ; i < 256; i++) {
char *pszCString =
ConvertPascaltoC(m_pPascalStrings[ i ]);
TStringAsData a_string(pszCString);
(*c_strings)[i] = a_string;
}
/* создаем преобразователь, который упорядочивает строки и
готовит их для передачи индексатору */
TCast *caster = new TStringCast(c_strings);
/* передаем индексатору строк преобразователь с нашими строками
второй параметр - уникальный идентификатор нашего объекта,
который будет приписываться к ключам в качестве значения */
succ = m_pIndexator->Start(caster, m_nDatabaseID);
/* освобождаем временные объекты */
delete caster;
delete c_strings;
}
return succ;
}
private:
/* прототипы методов, реализующих преобразование строк из
представления C в представление Pascal и обратно;
код функций не существенен для нашей темы, читатель без труда
сможет запрограммировать свой вариант */
char* ConvertPascaltoC(char *pszPascalString);
char* ConvertCtoPascal(char *pszCString);
};
Мы объявили один дополнительный атрибут - массив указателей на строки. Для простоты пояснения он сделан фиксированной длины. В конструкторе массив инициализируется нулями. В нем мы будем сохранять указатели на строки, предварительно преобразовав к формату Pascal. Самый интересный и объемный метод - CreateIndexData. Поскольку мы решили не создавать новый индексатор для наших специфических строк, то мы должны сперва явно конвертировать их в формат, принятый для строк в классе TOdbString и затем, через преобразователь, передать данные индексатору.
Теперь посмотрим как зарегистрировать новый тип данных, создать экземпляр объекта и сохранить его в базе данных- см. Листинг 2.
/* используем глобальную функцию GetManagerAddress() для получения
адреса информационного центра СУБД - объекта класса TOdbManager
*/
TOdbManager *pManager = GetManagerAddress();
/* получаем объект-регистратор типов базы данных */
TObjectRegistry *pObjectReg = pManager->GetObjectReg()
/* регистрируем наш тип TOdbPascalString, указывая его имя и адрес
функции, которая создает динамические экземпляры нашего класса
*/
pObjectReg->SomeRegister("TOdbPascalString",
TOdbPascalString::CreateFunc);
/* создаем объект посредством запроса к менеджеру */
TOdbObject *pObject =
pManager->SomeCreate("TOdbPascalString", null);
/* динамически преобразуем тип указателя поскольку CreateFunc
возвращает указатель на TOdbObject */
TOdbPascalString *pPascalString =
dynamic_cast<TOdbPascalString*>(pObject);
/* иной способ создания объекта класса TOdbPascalString -
непосредственное использование оператора new */
TOdbPascalString *pPascalString2 =
new TOdbPascalString(null, null);
/* заносим две строки в наш объект */
(*pPascalString)[0] = “The rains in Spain fall mainly in a plain”;
(*pPascalString)[1] = “What You have coded is what You put in DB”;
/* сохраняем объект в базе данных, метод New возвращает
идентификатор объекта в базе данных */
dword id = pPascalString->New();
/* наконец, удаляем объект */
delete pPascalString;
/* теперь читаем данные из базы, используя уникальный
идентификатор */
pPascalString2->Read(id);
/* читаем строки */
char *pszRain = (*pPascalString2)[ 0 ];
char *pszCode = (*pPascalString2)[ 1 ];
delete pPascalString2;
И, наконец, проиллюстрируем возможность клиента получить доступ к объекту TClientDatabase и блокировать базу данных - см. Листинг 3.
/* получаем адрес информационного центра СУБД */
TOdbManager *pManager = GetManagerAddress();
/* получаем указатель на клиентский образ базы данных с именем
“config” */
TClientDatabase *pBase = pManager->BindDatabase(“config”);
/* пытаемся заблокировать базу данных;
в случае успеха метод Lock возвращает true */
if(pBase->Lock(true)) {
/*...*/
/* обязательно отменяем блокировку */
pBase->Lock(false);
}
Таким образом создается, регистрируется и используется наш новый тип данных.
1.7 Заключение
Изложенные в настоящей работе принципы объектного проектирования базы данных и объектная технология обработки информации позволили разработать оригинальную структуру СУБД, сетевая версия которой, построенная по архитектуре “клиент-сервер”, воплотила в себе идеи многократного индексирования данных одного и того же объекта, а также механизмы полнотекстового поиска и обработки естественно-языковых запросов.
Известный факт, что объектная база данных очень хорошо подходит для областей, где требуется работа с данными сложной структуры.
Можно указать следующие области применения разработанной среды объектного проектирования ODB-Text и СУБД ODB-Jupiter:
- создание информационных систем для издательств. В этом случае очевидны такие преимущества как возможность хранения и поиска текстовой информации больших объемов, многопользовательская сетевая работа с документами, возможность хранения оригинал-макетов изданий, рекламной информации как OLE-объектов;
- создание электронных систем учета кадров для малых и средних предприятий. Чтобы построить такую систему достаточно при помощи Дизайнера форм создать карточку реквизитов документа, включив в нее названия полей необходимых анкетных данных, которые будут потом заполняться Программой-Клиентом. При такой организации в поле текста документа могут храниться автобиография, отсканированный листок по учету кадров и т.д. Главным достоинством такой системы учета кадров будет ее гибкость, то есть возможность быстро изменить ту информацию, которая хранится, ввести новые поисковые поля, исключить старую, потерявшую актуальность информацию;
- разработка электронных учебников и электронных учебных пособий. Успех такого использования программного комплекса определяется сочетанием возможностей открытой полнотекстовой системы (в первую очередь широких возможностей поиска информации) и возможностью хранить OLE-объекты, в виде которых можно сохранить любую аудиовизуальную информацию;
- создание разного рода библиотечных систем, в которых кроме чисто поисковой информации могут храниться отсканированные электронные копии тех или иных книг;
- организация специализированных хранилищ различной информации: медицинских карт, которые наряду с чисто текстовой информацией могут хранить и результаты различных анализов и исследований, если их удастся представить как OLE-объекты, баз данных о лекарствах, баз данных видеофильмов и слайдов, а также организация и ведение многих других баз данных в различных областях.
Следует указать, что ODB-Jupiter - СУБД “легкого” класса. Установка сервера не влечет смену оборудования так как минимальное требование микропроцессор 80386 и 8 Мб оперативной памяти. СУБД ориентирована на использование на персональных компьютерах, объединенных локальной вычислительной сетью. Конечно, предпочтительно выделить под сервер компьютер с достаточной вычислительной мощью, но система надежно работает даже не в оптимальных условиях.
Возможности объектной СУБД демонстрируются полнотекстовой информационно-поисковой системой “ODB-Jupiter”. Эта система, использующая объектную базу в качестве хранилища документов, эффективно обрабатывает одновременно десятки запросов, мегабайты данных, не требуя специального наращивания ресурса компьютера. Удачный опыт создания программ, работающих с СУБД ODB-Jupiter, позволяет надеяться на дальнейшее развитие уникальной российской разработки и расширение круга ее пользователей.
Список литературы:
- “OBJECT-ORIENTED DATABASE MANAGEMENT SYSTEMS”, editor Lon R. Dean, 1996, документ можно получить в Интернет по адресу http://www.dacs.com/forms/orderform.shtml.
- Андреев А.М., Березкин Д.В., Кантонистов Ю.А., “Объектно-ориентированная база данных ODB-Text”, “Мир ПК”, N 8, 1997, с. 49-52.
- Г. Буч, “Объектно-ориентированное программирование”, Москва, “Мир”, 1992
- М. Эллис, Б. Строуструп, “Справочное руководство по языку программирования C++”, “Мир”, 1992.
- М. Аткинсон и др., “Манифест систем объектно-ориентированных баз данных”, СУБД, N 4, 1995, с.142-155.
- Свидетельство РосАПО N 970171 о регистрации полнотекстовой информационно-поисковой системы “ODB-Text” версии 2.0, “Информационный бюллетень официальной регистрации программ для ЭВМ, баз данных и топологий интегральных микросхем”, из-во “Роспатенты”, II квартал, 1997 г.
- Андреев А.М., Березкин Д.В., Буйдов А.Ю., Смирнов Ю.М., "Объектные информационные системы (подход к проектированию)" Вестник МГТУ, Сер. Приборостроение N 2, М. Издательство МГТУ, 1995 г.
- Д. Райли, “Абстракции и структуры данных. Вводный курс.”, Москва, “Мир”, 1993г.
- Андреев А.М., Березкин Д.В., Куликов Ю.В., Смагин А.Ю., Смелов А.В. “Объектно-ориентированный подход к проектированию ГИС” , “Геодезия и Картография”, 1995 г., N2.