Доклад "Нейросетевая модель интеллектуальной обработки текстов". Основные тезисы В работе исследовано применение нейронных сетей соревновательного типа (ART и SOM) для решения задач обработки текста (классификация текста по темам и выявления ассоциативных связей между терминами). Использовались две основных модели представления текста: модель документ-термин и триграмная модель. В модели документ-термин текстовый документ представляется в виде вектора весов терминов. Множество документов представляется в виде матрицы, строками и столбцами которой являются соответственно векторы документов и терминов, что позволяет рассматривать отношения между терминами. В триграмной модели документ представляется в виде вектора частотного распределения триграмм в документе. Под триграммой понимается последовательность и трех последовательно идущих символов. Каждая триграмма кодируется уникальным номером Для решения задачи тематической классификации векторы документов подвергались кластеризации с использованием моделей нейронных сетей типа ART (теории адаптивного резонанса) и SOM (самоорганизующиеся карты). В случае ART в процессе обучения сети определяется принадлежность документа к одному из кластеров, который представляется одним нейроном выходного слоя, количество которых определяется автоматически во время обучения. В конце обучения сети веса выходных нейронов представляют собой вектор прототипа определенной темы, и документ можно отнести к этой теме, если он участвовал в обучении данного нейрона, или если мера близости векторов документа и нейрона достаточно высока. В случае SOM в выходном слое сети имеется фиксированное количество нейронов, которые в результате обучения образуют топологически связанные группы, внутри которых векторы весов нейронов имеют близкие значения. Образуется т.н. тематическая карта, в которой темам соответствуют группы нейронов, причем документы из близких тем обучают топологически близкие нейроны. Т.о. модель SOM позволяет формировать визуальное представление семантической структуры множества документов, что в тоже время усложняет задачу формального выделения кластеров. Большее количество нейронов выходного слоя по сравнению с ART повышает вычислительную сложность SOM. Существуют методы, позволяющие использовать преимущество обоих типов сетей. Один из вариантов – непосредственная организация трехслойной сети, у которой первый слой – входной, второй – слой SOM, третий – слой ART. Слой SOM – статический и содержит фиксированное количество нейронов, слой ART – формируется динамически. Входные вектора отображаются на слое SOM в соответствии с их взаимной близость., а слой ART формирует из образовавшихся групп нейронов, желаемые кластеры. Для кластеризации документов использовалось три модели их векторного представления:
В качестве меры близости между векторами использовалось скалярное произведение. При использовании моделей представления 1 и 3 удовлетворительные результаты удалось получить только при классификации документов из довольно узко специализированных тем, таких как сводки УВД и банковские документы. Точность классификации, при этом, в значительной мере зависела от порядка подачи документов обучающей выборки. Модель 2 дала значительно лучшие результаты, позволяя, например, выделить в отдельную тему документы социального законодательства, относящиеся к конкретной местности, при этом результат слабо зависел от порядка обучения. Для решения задачи выявления ассоциативных связей между терминами применялась кластеризация векторов терминов при представлении множества документов согласно модели 1. Использовалась мера близости Применение для кластеризации векторов терминов методов, применяемых для кластеризации векторов документов без изменений неприемлемо по следующей причине. Распределение терминов по документам очень неравномерно, т.е. большая часть терминов содержится в небольшом количестве документов, и очень мало терминов содержится в большом количестве документов. Между терминами A и В может существовать семантическая связь, но если Для решения этой проблемы множество терминов разбивается на частотные группы в порядке убывания частоты: T = T1 È
T2 ... È
Tr. T1 объединяет наиболее частые термины, в то время как Tr – наиболее редкие. Другие множества терминов образуются следующим образом: T12 = T1 È
T2, T123 = T1 È
T2 È
T3, ... T123..r = T1 È
T2 È
T3... È
Tr. Каждое из образованных подмножеств подвергается кластеризации отдельно. Создание ассоциативных связей между всеми терминами внутри образовавшихся кластеров не является эффективным, т.к. в этом случае будет произведено слишком много незначащих ассоциаций. Требуется выбрать для каждого термина только небольшое количество значительно связанных терминов. Пусть термин
где ci(t) - кластер t в сети Ti, tj*1,Ti – наиболее близкий к t широкий термин в Ti, tj*1,сi(t)– наиболее близкий к t широкий термин в кластере t (согласно сети Ti), tj*2,Ti – наиболее близкий к t узкий термин в Ti, tj*2,сi(t) – наиболее близкий к t узкий термин в семантическом классе t (согласно сети Ti). Экспериментальные исследования выявили, что сети типа SOM требуют более высоких вычислительных затрат и несколько большей трудности выделения кластеров, чем нейросети типа ART. Исследования производились для множества документов, содержащих сводки УВД и банковские документы. В результате были получены в частности такие пары связанных терминов (первым указан широкий термин): банк–акции, банк–фонд, бумаг–акций, задержаны–преступление, изъято–задержаны, которые могут быть использованы, например, для расширения поисковых запросов.
|

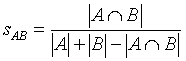 , где
, где 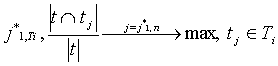 ,
, 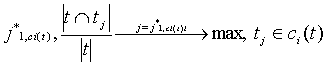 ,
,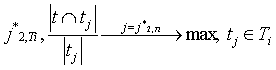 ,
, 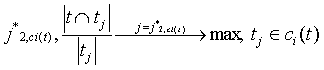 ,
,